deeplearning.ai深度学习笔记(Course5 Week3):Sequence models & Attention mechanism
本周是deeplearning.ai系列的最后一节课,以机器翻译为例,介绍了seq2seq模型,扩展分析了beam search、bleu score和attention model。最后简要介绍了语音识别和触发词检测。
1- Various sequence to sequence architectures
1.1- Basic Models
这周将学习序列到序列(seq2seq, sequence to sequence)模型,seq2seq在序列到序列的转换方面非常有用,尤其是机器翻译和语音识别。
seq2seq模型主要来源于如下两篇论文:
- Sutskever et al., 2014. Sequence to sequence learning with neural networks
- Cho et al., 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation
我们先从最基本的模型开始。假设我们有一个机器翻译的任务,将法语翻译成英语,比如:
法语:Jane visite l’Afrique en septembre. 英语:Jane is visiting Africa in September.
通常,我们用\(x\)和\(y\)将输入和输出表示为序列,如下:

我们的目标就是,训练一个神经网络,输入序列\(x\),输出序列\(y\)。 首先,我们先创建一个称为编码器(encoder) 的RNN(具体可以是GRU或LSTM),并把法语序列输入到该网络。当encoder将所有单词都“吞下”后,在最后的时间步的状态输入到一个称为解码器(decoder) 的RNN,该RNN输出翻译后的英语,如下图:
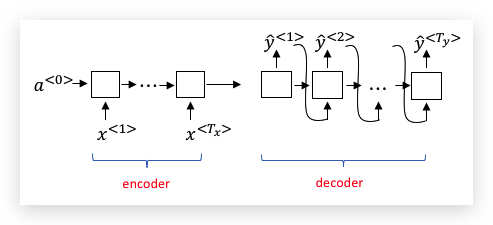
在给出足够的法语和英语对应文本的情况下,这个模型的效果相当不错。该模型简单的使用一个编码网络,将输入的法语编码,然后用一个解码网络生成对应的英语翻译。
和上面非常类似的架构,同时也应用于图像描述(image captioning)。比如,下面输入一张图片,给出图片的描述(即看图说话):
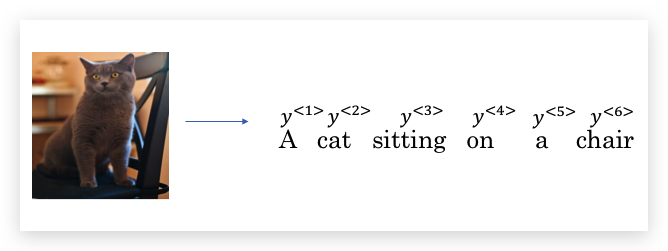
结合之前我们学习的CNN网络,我们先用CNN对图片进行编码,比如用预训练好的AlexNet得到4096维的编码,然后将编码输入到RNN作为解码器,输出对图像的描述:
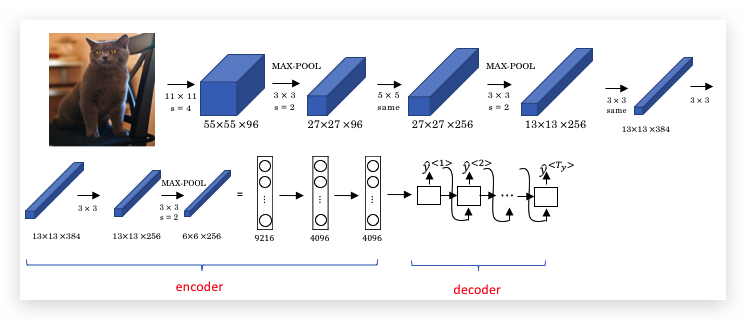
上面的图片描述模型,几乎被多篇论文同时提出:
- Mao et. al., 2014. Deep captioning with multimodal recurrent neural networks
- Vinyals et. al., 2014. Show and tell: Neural image caption generator
- Karpathy and Li, 2015. Deep visual-semantic alignments for generating image descriptions
上面的基本seq2seq模型,和之前讨论的使用语言模型产生新文本还有差别。主要在于,我们并不下午随机的选择翻译或图片描述,而是希望选择可能性最大的。接下来我们将介绍如何做到。
1.2- Picking the most likely sentence
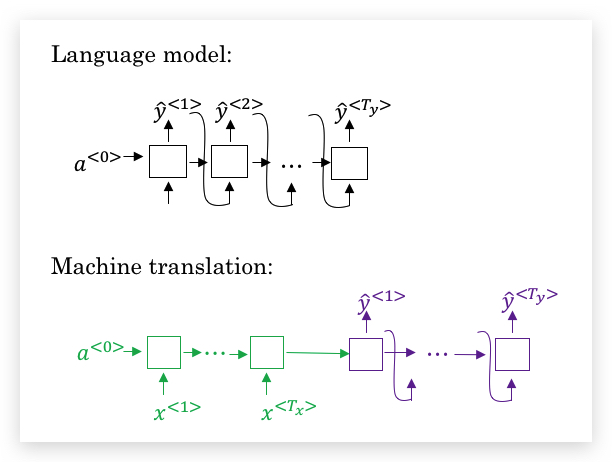
seq2seq翻译模型和先前讨论的语言模型既有些相似,也有很大不同。我们可以将机器翻译看做构建一个条件语言模型(conditional language model)。
下图是两个模型的对比,我们可以看出机器翻译模型的decoder部分和语言模型十分类似,唯一差别在于,机器翻译的最初输入状态来源于encoder,而语言模型的输入固定为\(a^{<0>}\)。
语言模型计算的是概率:
\[P(y^{\<1>},...,y^{\<T_y>})\]而机器翻译模型,计算的是条件概率(这也是其称为条件语言模型的原因):
\[P(y^{\<1>},...,y^{\<T_y>}| x^{\<1>},...,x^{\<T_x>})\]解码器随机采样,可能导致翻译结果时好时坏,因此我们不能随机的抽样出翻译结果,而是找到令上面条件概率最大化的翻译,即:
\[\text{arg} \ \text{max}\_{y^{\<1>}, ..., y^{\<T_y>}}P(y^{\<1>}, ..., y^{\<T_y>} | x)\]因此在开发机器学习系统时,你要做的事情之一就是使用算法求出使得上面条件概率最大的\(y\)。其中最常用的算法之一是集束搜索(Beam Search)。
在学习Beam Search之前,我们先看一下为什么不用贪心搜索(greedy search),贪心搜索只是最大化解码器当期时间步的条件概率,而我们希望的是整个语句的条件概率最大。贪心算法很容易陷入次优解,所以不适合。
与greedy search对应的是另外一个极端:对全体空间搜索。比如翻译的语句长度是10,词汇表是10000,则需要搜索\(10000^{10}\)个句子,这个搜索量和让猴子敲出莎士比亚文集没什么区别,显然是不现实的。
1.3- Beam Search
我们还以上面的法语翻译为例,讲解Beam Search的步骤:
- 首先看第一个单词的条件概率\(P(\hat y^{<1>}|x)\),并选择概率最大的3个单词作为候选,这里个数3称为集束宽(beam width),代表解码器中每个时间步候选的单词个数,记作\(B\)。具体上面的例子,可能选到了3个候选单词是:in, jane, september。
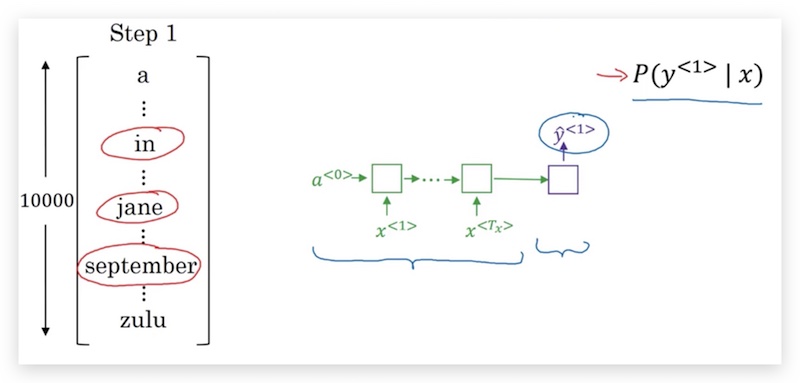
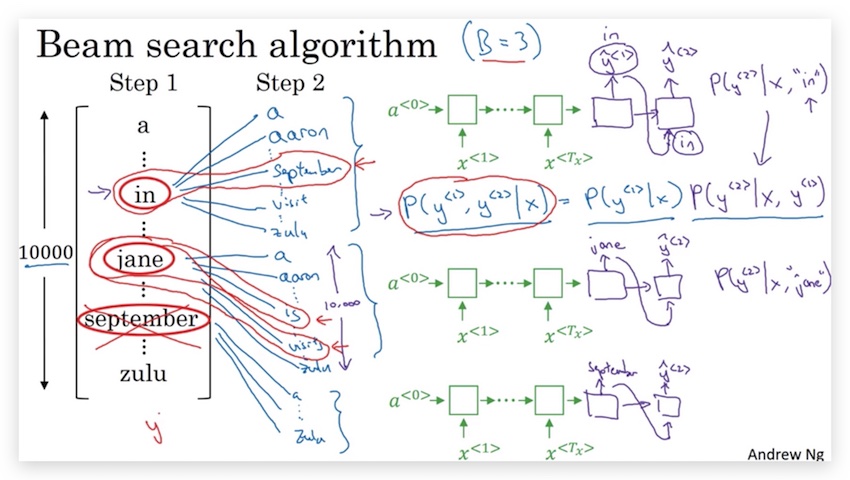
- 然后分别考虑第1个单词是上面3个候选单词之一的条件下,第2个单词的概率\(P(\hat y^{<2>}|x, \hat y^{<1>})\)。比如第一个单词是in的概率\(P(\hat y^{<2>}|x, \text{‘in’})\)。然后再选出构成前两个单词概率最大的3个组合,其概率计算为:
\(P(\hat y^{\<1>}, \hat y^{\<2>}|x) = P(\hat y^{\<1>}|x) P(\hat y^{\<2>}|x, \hat y^{\<1>})\)
由于\(B=3\),因此我们在这一步会考虑3x10000种组合(第一步对应3个单词,第二步对应词汇表10000个单词),并选择其中概率最大的3个。最终可能的候选是:in september, jane is, jane visits(第一个单词是september的情况已经被剔除了)。我们将30000的搜索范围,收缩为3个候选。
- 第3步和第2步类似,可能继续得到3个候选:in september jane, jane is visiting, jane visits africa
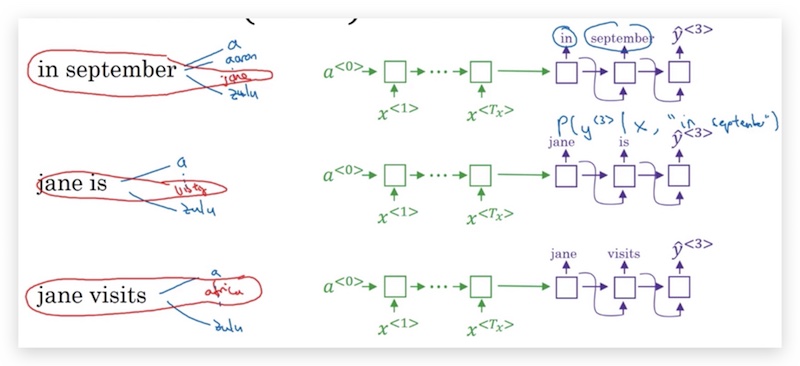
特别的,如果\(B=1\),beam search就退化为了贪心搜索。
1.4- Refinements to Beam Search
下面介绍一些对Beam search算法的优化。
- 长度归一化(length normalization)
我们知道Beam Search的优化目标是: \(\text{arg} \ \text{max}\_{y^{\<1>}, ..., y^{\<T_y>}}P(y^{\<1>}, ..., y^{\<T_y>} | x)\)
展开为条件概率的乘积: \(\text{arg max} \prod^{T_y}\_{t=1} P( y^{\<t>} | x, y^{\<1>}, ..., y^{\<t-1>})\)
实践中,每个因子通常是远小于1的概率,经过一连串的乘积会导致结果为一个很小很小的数字,导致下溢(underflow),即计算机没法精确表示。因此实际操作中,为将优化目标取对数,规避下溢问题。我知道对数函数是单调递增的,因此两个优化目标等价,即:
\[\text{arg max} \sum^{T_y}\_{t=1} \log P( y^{\<t>} | x, y^{\<1>}, ..., y^{\<t-1>})\]观察上面的优化目标,可以发现优化目标倾向于选择长度短的输出序列,因为每个条件概率都小于1,因此序列越短总的概率越大,这并不是我们希望的。因此我们再增加一个系数对太短的语句惩罚,简单点就用输出序列的总长度做一下平均:
\[\text{arg max} \frac{1}{T_y} \sum^{T_y}\_{t=1} \log P( y^{\<t>} | x, y^{\<1>}, ..., y^{\<t-1>})\]实践中,一般我们会再加一个更柔和的处理方法,即\(T_y\)上加上指数\(\alpha\):
\[\text{arg max} \frac{1}{T_y^\alpha} \sum^{T_y}\_{t=1} \log P( y^{\<t>} | x, y^{\<1>}, ..., y^{\<t-1>})\]如果\(\alpha=1\),就完全用长度来归一化;如果\(\alpha=0\),就是没有做归一化。一般会选择一个中间值。\(\alpha\)也是算法的一个超参,需要不断调整来得到最好的结果,并没有理论性验证。
上式也称为归一化对数概率目标(normalized log probability objective)或归一化对数似然目标(normalized log likelihood objective)。
总结一下如何运行beam search算法。运行beam search,会得到一系列长度的翻译语句,假如限制输出语句最长为30个单词,则得到长度从1到30的语句的概率。每个长度都会保留\(B\)个概率最高的语句。然后针对这些所有可能的输出语句,用上式给他们打分,取得分最高的一个语句作为翻译结果。
- 如何选择参数\(B\)
很显然,\(B\)越大,取得的结果越良好,但计算量和内存需求也更大。
前面的讲解汇总\(B\)取3是比较小的,在产品中,经常可以看到\(B\)取10的情况。\(B\)的大小也是取决于应用场景的,比如论文中会看到\(B\)取值1000或者3000,主要是为了压榨出全部性能。
但\(B\)的提升的边际效益会递减,从1提升到3或者10的收益,要比从1000提升到3000的收益大得多。
另外,需要明白的是beam search和计算机中的其他搜索算法,如广度优先搜索(BFS)、深度优先搜索(DFS)不一样,它们都是精确的搜索算法。而beam search是一个近似搜索算法,并不保证搜索到实际的最大值。
1.5- Error analysis in beam search
我们知道beam search是一个模糊的启发式搜索算法,并不保证搜索到实际的最大值,因此就需要对beam search的结果进行错误分析。我们需要分析错误的原因是RNN模型还是beam search,来指导我们的模型优化。
下面仍用法语翻译的例子,我们将人类翻译的结果记为\(y^*\),算法翻译的结果记为\(\hat y\):

虽然对RNN增加训练样本或者增加beam search的参数\(B\)对翻译结果总是没有坏处的,但我们要知道瓶颈在哪,才能有的放矢。
| 方法很简单,直接用RNN去计算人类翻译和算法翻译的概率,即比较\(P(y^* | x)\)和\(P(\hat y | x)\)做判断: |
| * 如果\(P(y^* | x) > P(\hat y | x)\),说明beam search效果不好,没有搜索到概率更大的翻译语句。 |
| * 如果\(P(y^* | x) \le P(\hat y | x)\),说明RNN效果不好,较好的翻译语句没有得到更大的概率。 |
基于上面的原则,我们做一个表格,对一定数量的错误案例进行分析,统计RNN和beam search出错的占比,得到模型的瓶颈在哪里,然后针对其优化。
做一个错误的分析表,选取一定的数量看一看。
1.6- Bleu Score
TODO: 衡量机器翻译结果和人工翻译结果的相似性(重合性) 如果只翻译出一个单词呢? 这一集的视频太水了,都懒得剪辑了。
单值评价
1.7- Attention Model Intuition
注意力模型(Attention Model) 是深度学习领域最有影响力的思想之一。
- 长序列问题
之前我们使用的RNN模型,都是encoder完整输入所有待翻译的序列后,decoder再输出翻译后的序列。而面对长句子时,人类翻译者并不会一次性阅读完整个句子才翻译,而是拆分为一小段一小段的,逐段翻译,因为人们很难一次性记住很长的句子。
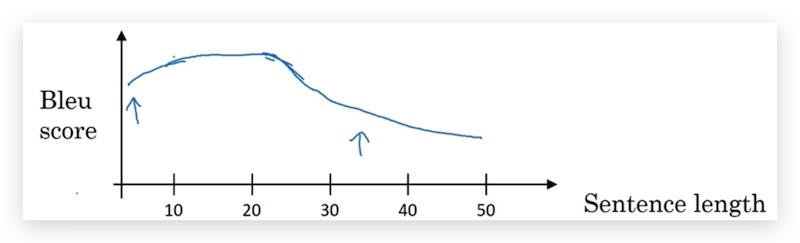
我们发现,随着句子的增长,Bleu Score开始降低:
- Attention model
使用注意力模型可以显著解决这个问题,attention model受人类翻译的启发,我们并不希望神经网络每次记忆很长的文字,而是每次处理一段文字,这样在处理长句的情况下Bleu Score不降低。
(我有个疑问,为什么一定要和人一样,人是因为有记忆限制的缺陷。如果不用注意力模型,翻译效果会不会比人更好?)
首先,我们使用一个BRNN作为编码器,BRNN输出每个单词丰富的特征:
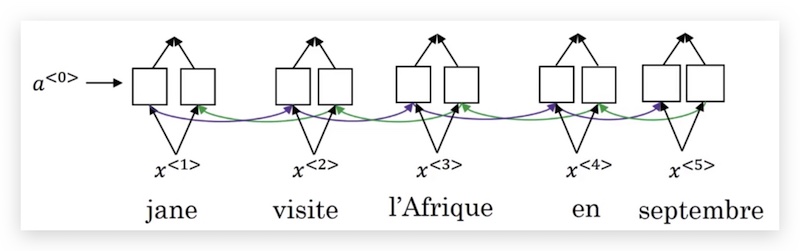
然后我们用另外一个单向RNN作为解码器,为了避免两个RNN的激活函数混淆,此处解码器RNN用\(s\)表示激活函数。
我们的问题是,解码器的每一个时间步应该查看被翻译语句的哪些部分,即比如\(s^<1>\)应考虑编码器哪些输出。在注意力模型里,我们使用注意力权重(attention weights) 来表示对句子每个部分的权重,这个权重记为\(\alpha^{<t,t’>}\),其中上标含义是,解码器的第\(t\)个时间步,对编码器第\(t’\)个输出的注意力权重。我们用\(c\)表示编码器激活函数在注意力权重加权后的结果,将\(c\)输入到解码器用来生成翻译语句,如下图:
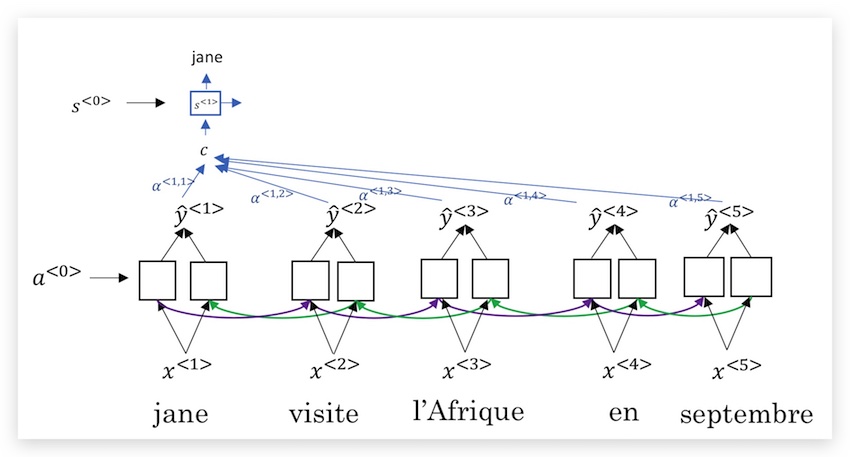
第二个输出也是类似,激活函数\(s^<2>\)的输入来自注意力权重加权的新结果\(c\),当然同时会将上一个时间步输出的翻译结果也加入;以此类推,如下图:
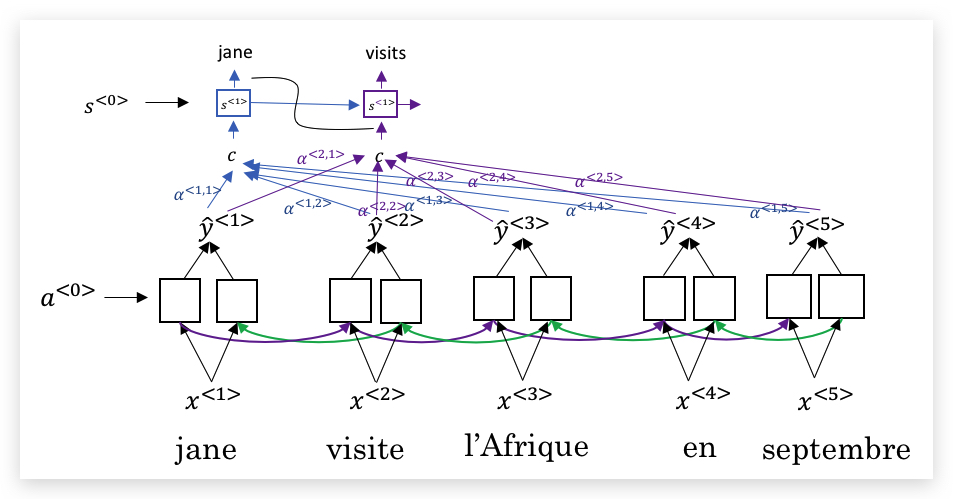
TODO: 注意力模型的思想主要来源论文:[Bahdanau et. al., 2014. Neural machine translation by jointly learning to align and translate]
1.8- Attention Model
上一节介绍了注意力模型的Intuition,现在我们形式化定义。模型和上一节一样,下面是一个BRNN的编码器,上面是一个多对多的RNN解码器,如下图:
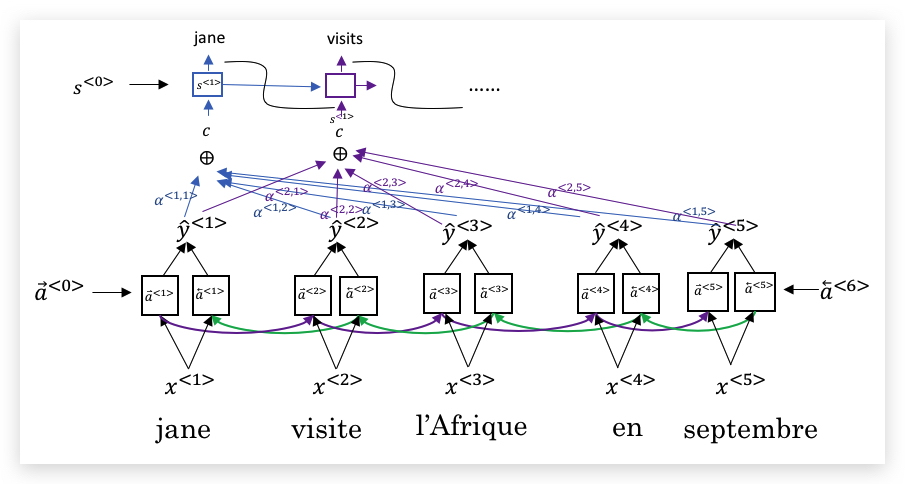
其中每一个输出,单独拿出来如下:
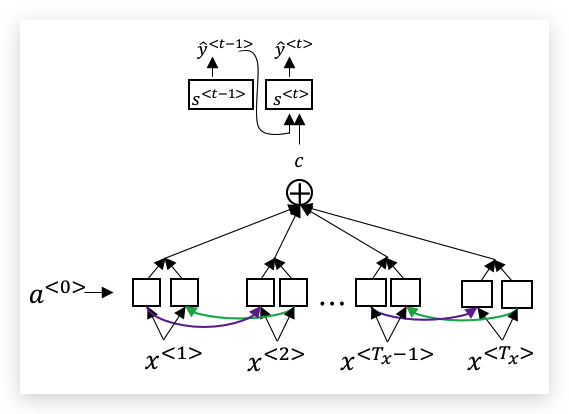
我们把编码器BRNN的每个单元的前向和后向激活函数分别记为\(\overrightarrow a^{<t’>}\)和\(\overleftarrow a^{<t’>}\),为了便于说明,我们合并记为\(a^{<t’>}\),即:
\[a^{\<t'>} = (\overrightarrow a^{\<t'>}, \overleftarrow a^{\<t'>})\]对解码器的第\(t\)个时间步,其输入来自编码器的注意力加权\(c\),以及前一个时间步的激活函数\(s^{<t-1>}\),输出\(y^{<t-1>}\)。其中\(c\)的计算为:
\[c^{\<t>} = \sum_{t'}\alpha^{\<t,t'>} a^{\<t'>}\]显然注意力权重\(\alpha\)要满足大于0,并且和为1:
\[\sum_{t'}\alpha^{\<t,t'>} = 1\]\(\alpha^{<t,t’>}\),即代表了\(y^{<t>}\)对\(a^{<t’>}\)的注意力大小。这个权重的计算如下:
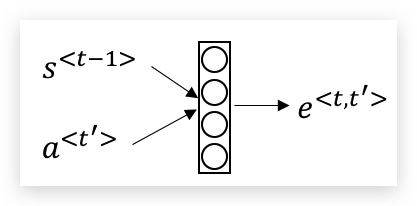
\[a^{\<t,t'>} = \frac{\text{exp}(e^{\<t,t'>})}{\sum^{T_x}\_{t'=1} \text{exp}(e^{\<t,t'>})}\]其中\(e\)的计算,使用一个小神经网络计算,如下:
2- Speech recognition - Audio data
2.1- Speech recognition
语音识别问题,就是将一段音频片段,自动转换为文字,seq2seq模型也可以应用于此。
语音识别问题,在早期是通过音位(phonemes)来构建的,需要手工工程设计的基本单元(hand-engineered basic units of cells)。我们会将单词拆分为基本的音位,如the拆分为th和e的音,而quick拆分为k w i k四个音。语音学家认为用户音位表示法(phonemes representations)是做语音识别的好办法。
但在end-to-end的深度学习模型中,已经没有必要人工去分析音位了。通过大量的文本语音数据集,运用深度学习算法大大推进了语音识别的进程。最好的商业系统,可能会使用长达10万小时的音频训练。
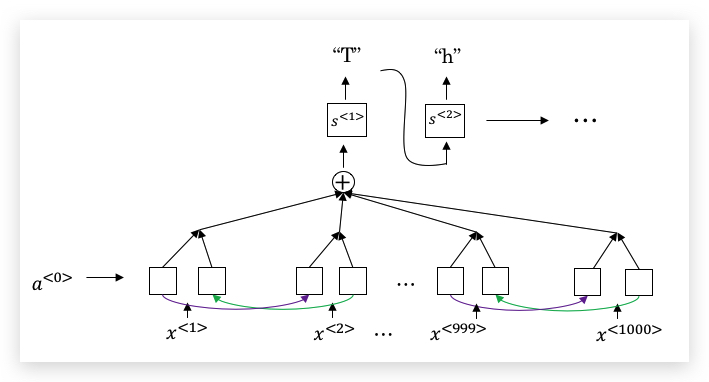
当然,我们可以使用attention model训练语音识别:
还有一种方法效果非常不错,它使用了CTC(Connectionist Temporal Classification)损失函数。下面简要介绍:
假如我们要识别的语音对应的内容是”the quick brown fox”,
我们将用一个输入和输出大小相同的RNN(这里使用单向RNN说明,实践中会用BRNN):
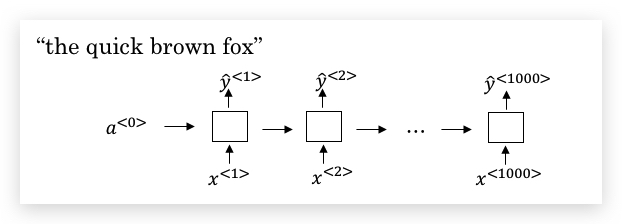
需要注意的是,输入的时间步通常会比输出的时间步大很多。举个例子,10秒钟的音频,如果用100Hz采样,则每秒就会产生100个样本,于是10秒的音频,会产生1000个输入,但输出的字符肯定没有这么多。CTC的做法是,允许RNN产生类似如下的输出:
ttt_h_eeee_ _ _ <space> _ _ _qqq_ _ _……
其中_表示空白符,<space>表示空格。将空白符分隔的字符折叠起来,然后去掉空白符,则得到了输出文本:
the quick brown fox
这样就允许整个网络有1000个有重复的字母的输出,但最终仍能得到短得多的文本输出。
2.2- Trigger Word Detection
相比通用的语音识别系统需要大量训练数据,触发词检测(Trigger Word Detection)要简单得多,使用较小的数据量即可训练。
触发检测系统,主要用于一些设备的唤醒,比如苹果的Siri、智能音箱等。下面介绍一种实现算法。
现在有一个这样的RNN结构,我们要做的就是把一个音频片段计算出它的声谱图特征(spectrogram features),得到特征向量\(x^{<1>}, x^{<2>}, x^{<3>}, …\),然后输入到RNN中,最后要做的就是定义目标标签\(y\)。假如某一点是出现了触发词,那么在这之前的标签都设置为0,而这一点的设置为1;如果过了一段时间,触发词再次被说了一次,再次把这个点设置为1。
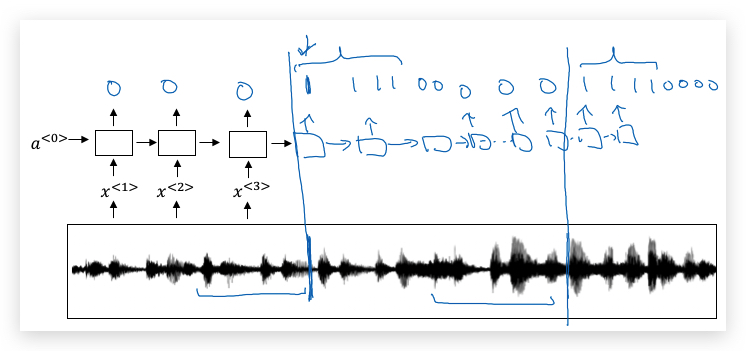
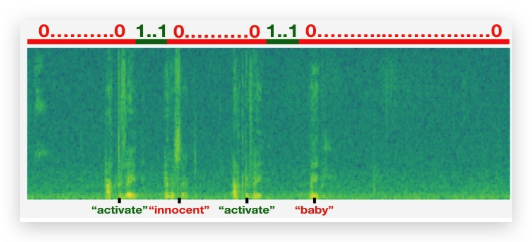
上面的算法有一个明显的缺点是,构建了一个很不平衡的训练集,即0比1要多得多。但有一个简单粗暴的办法可以解决,是的训练更容易。我们在一个时间步上输出1后,在变回0之前多输出几次1,或者在固定的一段时间内输出多个1.
3- Conclusion
3.1- Conclusion and thank you
deeplearning.ai课程结束了!与开篇的AI is the new electricity的口号相呼应,Andrew Ng激励我们:
Deep learning is a super power! If that isn’t a superpower I don’t know what is.

-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/deeplearning-ai-notes-course5-week3 欢迎指正或在下方评论。
毛帅
{Code, Thoughts, Sharing}