deeplearning.ai深度学习笔记(Course5 Week1):Recurrent Neural Networks
| 介绍了RNN相关的模型,包括基本RNN、GRU、LSTM、BRNN以及深度RNN。顺便介绍了语言模型、采样生成新序列。相比以往,本周信息量极大,整理完后差点要吐-_- | 。 |
1- Recurrent Neural Networks
1.1- Why sequence models
序列模型(Sequence Model)是深度学习最令人激动的领域之一。循环神经网络(Recurrent Neural Network, RNN)也已变革了语音识别(Speech Recognition)、自然语言处理(Natural Language Process, NLP)等领域。
我们首先看几个序列模型非常适用的例子,它们是一些序列数据(Sequence Data)的例子:
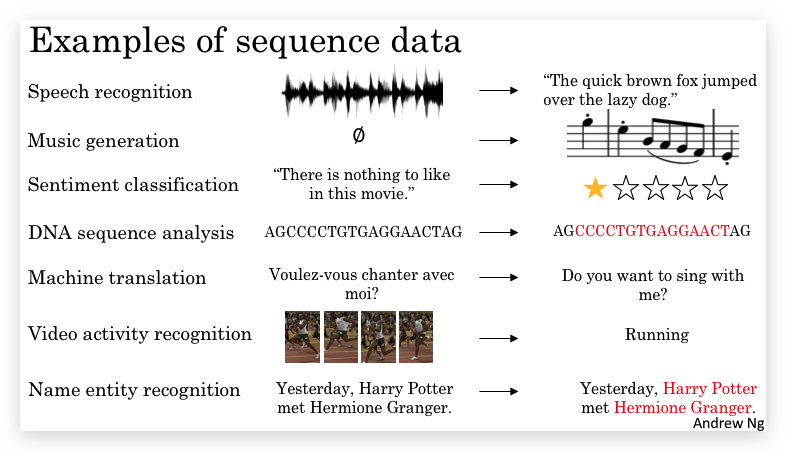
这些问题都可以通过有监督的学习(Supervised Learning),通过给定输入X和输出Y进行训练。这几个例子的区别是,有些是X和Y都是序列数据,有些只有X或Y是序列数据,另外有些X和Y虽然都是序列数据,但序列的长度并不相等。
1.2- Notation
本节将介绍在序列模型中使用的数学记号。对于输入序列数据\(x\),我们用带尖括号的上标表示序列第几个元素,比如\(x^{<1>}\)表示第一个元素,习惯上我们用\(x^{<t>}\)表示第\(t\)个元素。对应的,输出数据可以表示为\(y^{<1>}\)、\(y^{<t>}\)等形式。
另外,我们用\(T_x\)和\(T_y\)分别表示输入数据\(x\)和输出数据\(y\)的序列长度(length of sequence)。
与以前一样,我们还用带小括号的上标表示样本的序号,因此有:
- \(x^{(i)<t>}\)表第\(i\)个输入数据的第\(t\)个序列元素。
- \(y^{(i)<t>}\)表第\(i\)个输出数据的第\(t\)个序列元素。
- \(T^{(i)}_x\)表示第\(i\)个输入数据的序列长度。(每条数据的序列长度可以不一样)
- \(T^{(i)}_y\)表示第\(i\)个输出数据的序列长度。
下面以Name entiy rcognition的案例,输入一句话,识别文本中的人名。输入数据有9个单词,因此输入数据被拆分成9个序列元素,输出数据也是9个序列元素,1表示是人名,0表示不是人名。相关记号举例如下:

在NLP领域,如何表示单词?首先我们建立一个向量,包含常用的词汇,形成一个词汇表(vocabulary)。词汇表的大小根据应用决定,可以是数十万,也可能达到百万级别。本例中我们假设词汇表大小是1万以说明。
有了词汇表,我们就可以将任何单词以为one-hot向量的形式表示。所谓one-hot向量,是一个和词汇表维度相同的向量,并且该向量里只有和单词在词汇表里对应位置的数字是1,其他数字全是零。举个例子,假如单词“Harry”在上述1万维的词汇表中处于第4075个位置,则Harray可以表示为1万维的向量,仅有第4075个分量是1,其他都是0。
由于总会出现不在词汇表中的单词,所以词汇表里会补充一个用以表示所有未知单词的符号,比如记为<UNK>。
为什么要用one-hot向量,我的理解是为了和概率模型统一,后面定义Loss function会很方便。向量每个分量表示词汇表里对应单词的概率,而one-hot则用概率的角度表示其代表某个单词(因为概率为1嘛)。
1.3- Recurrent Neural Network Model
如何建立一个模型映射序列模型中X到Y的映射呢?一个可能的想法是使用标准神经网络(Standard NN),比如将\(T_x\)个one-hot向量输入到一个标准神经网络后,经过若干隐藏层,输出\(T_y\)个变量,但并不奏效,主要有几个问题:
- 不同的样本,输入和输出的长度并不相同,即不同的样本\(T_x\)和\(T_y\)不固定。
- 更重要的是,这种网络无法在文字的不同位置共享features。比如网络学习到Harry在第一个位置可能是人名,但在其他位置却无法识别了。这一点和CNN是类似的。
- 模型中的参数太多,计算量巨大(每个单词可都是1万维的one-hot向量哦)。
我们可以通过循环神经网络(Recurrent Neural Network,RNN)解决上述问题,下面是RNN的典型结构图:
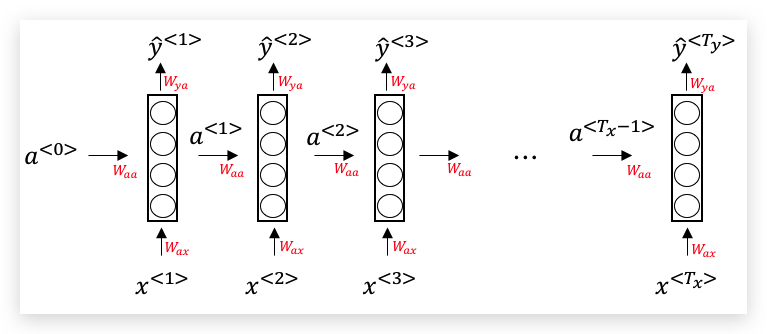
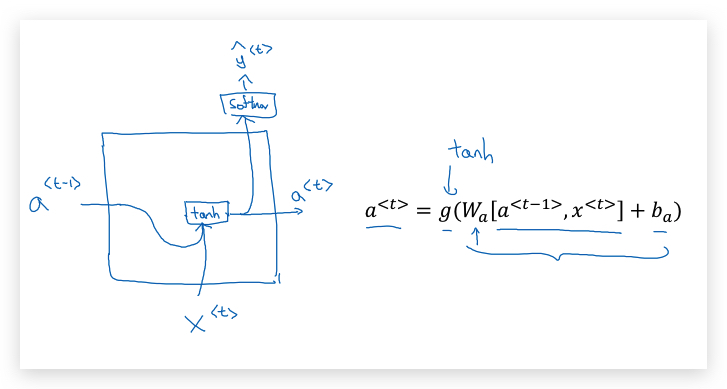
当\(x^{<t>}\)输入到当前时间步(time step)对应的隐藏层时,同时会将上一个时间步的激活函数\(a^{<t-1>}\)加入计算,从而产生\(\hat y^{<t>}\)。特别的,第一层的输入\(a^{<0>}\)一般是定义为0向量。
RNN的关键点是,后面的每个序列元素,比如\(\hat y^{<3>}\),其输入信息不仅来源于当前序列元素\(x^{<3>}\),还间接来源于前面所有序列元素\(x^{<2>}\)和\(x^{<1>}\) 。
RNN从左到右扫描数据,用于每一个时间步的参数是共享的,即上图中3组红色参数,在每个时间步中是一样的。
关于参数W下标的两个字母的说明: 下标的第1个字母与输出变量的名字对应,第2个字母与该参数相乘的变量对应。比如\(W_{ax}\)表示它是与\(x^{<t>}\)相乘的系数,输出结果是\(a^{<t>}\)。
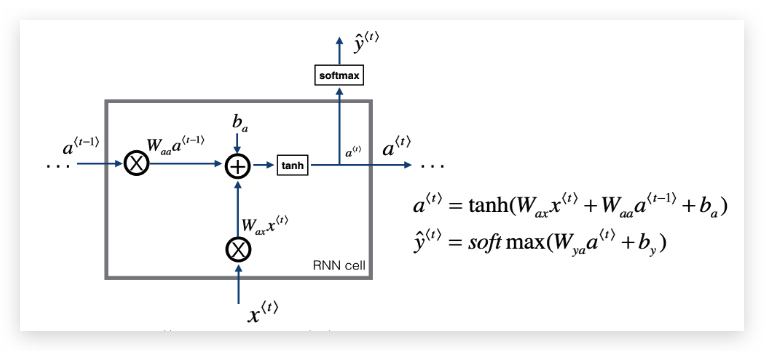
Forward Propagation的计算过程: 首先: \(a^{\<0>} = 0\)
计算第一个时间步: \(a^{\<1>} = g_1(W_{aa} a^{\<0>} + W_{ax} x^{\<1>} + b_a)\) \(\hat y^{\<1>} = g_2 ( W_{ya} a^{\<1>} + b_y )\)
一般的,第\(t\)个时间步: \(a^{\<t>} = g_1(W_{aa} a^{\<t-1>} + W_{ax} x^{\<t>} + b_a)\) \(\hat y^{\<t>} = g_2 ( W_{ya} a^{\<t>} + b_y )\)
其中\(g1\)通常选用tanh或ReLU,\(g2\)根据输出需要,可选用sigmoid或softmax。
以上过程可以用下面的RNN单元表示:
为了表示更复杂的模型,我们对RNN标记做一定的简化。使用分块矩阵的方法,我们将下式做简化:
\[W_{aa} a^{\<t-1>} + W_{ax} x^{\<t>}\]将\(W_{aa}\)和\(W_{ax}\)横向堆叠,形成新的矩阵 \(W_{a} = \[W_{aa} \vdots W_{ax}]\)
将\(a^{<t-1>}\)和\(x^{<t>}\)竖向堆叠,形成新的矩阵:
\[[a^{\<t-1>}, x^{\<t>}] = \\left[ \\begin{matrix} a^{\<t-1>} \\\\ x^{\<t>} \\\\ \end{matrix} \\right]\]因此有: \(W_{aa} a^{\<t-1>} + W_{ax} x^{\<t>} = W_{a} [a^{\<t-1>}, x^{\<t>}]\)
最终以下forward propagation的式子
\(a^{\<t>} = g_1(W_{aa} a^{\<t-1>} + W_{ax} x^{\<t>} + b_a)\) \(\hat y^{\<t>} = g_2 ( W_{ya} a^{\<t>} + b_y )\)
被简化为:
\(a^{\<t>} = g_1(W_{a} [a^{\<t-1>}, x^{\<t>}] + b_a)\) \(\hat y^{\<t>} = g_2 ( W_{y} a^{\<t>} + b_y )\) (第二个式子\(W_{ya}\)同时简化为了\(W_{y}\))
补充一点,RNN的一个弱点是,后面的元素能参考前面元素的信息,而前面的元素却对后面的元素一无所知。举个例子,对于如下两句话,我们需要根据后面的信息判断Teddy是否是一个人的名字,而对RNN来说,两句话在判断Teddy是否是人名时,都只能看到He said两个单词,是没有区别的。为此,衍生了双向RNN(bi-directional RNN, BRNN),后面会介绍。
He said, “Teddy Roosevelt was a great President.” He said, “Teddy bears are on sale!”
1.4- Backpropagation through time
虽然使用深度学习框架可以自动完成RNN的反向传播,但本节还是粗略的介绍一下RNN的反向传播。
定义Loss Function: 第\(t\)个时间步的Loss Function为(与logistic regression类似,采用交叉熵损失cross entropy loss) \(L^{\<t>}(\hat y^{\<t>}, y^{\<t>}) = -y^{\<t>}\log\hat y^{\<t>} - (1 - y^{\<t>})\log(1-\hat y^{\<t>})\) 所有时间步Loss Function构成一条序列数据的Loss Function: \(L(\hat y, y) = \sum^{T_x}\_{t=1} L^{\<t>}(\hat y^{\<t>}, y^{\<t>})\)
下面是RNN的forward propagation和backpropagation的示意图绿色是forward propagation,红色是backpropagation。
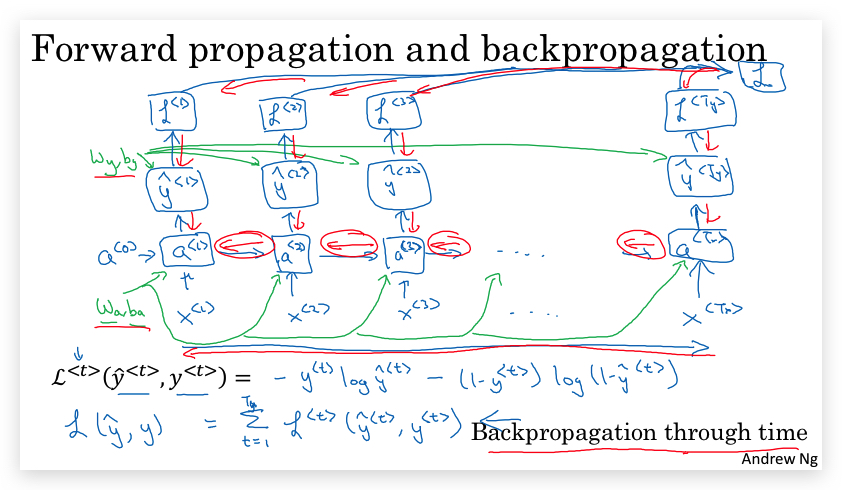
对于backpropagation会在不同时间步之间从右向左计算,因此这个过程也有一个很酷的名字:穿越时间的反向传播(Backpropagation through time)。
1.5- Different types of RNNs
虽然前面举例都是输入和输出相等的序列模型,但正如最初介绍的,RNN中\(T_x\)并不是总是等于\(T_y\),下图用绿色标注了输入和输出维度的关系:

因此也产生了不同类型的RNN结构:
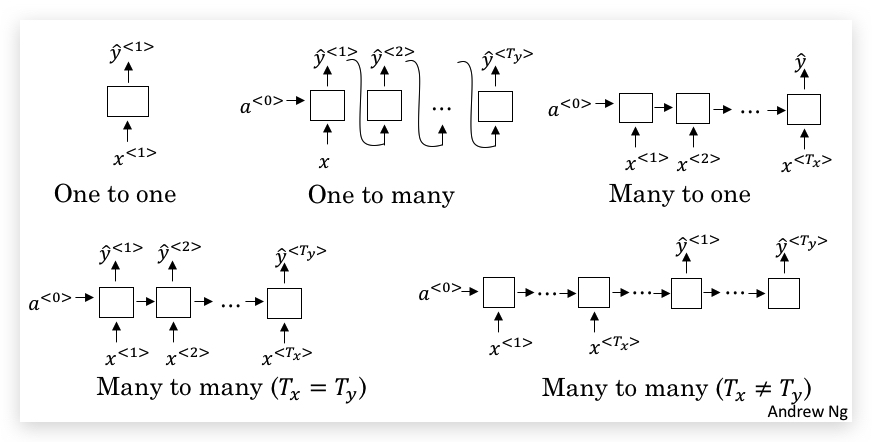
- 左下角就是之前接触的最基本的RNN,Many to many并且\(T_x = T_y\)。
- Many to one结构,与标准结构相比,将每个时间步的输出都去除,只保留最后一步的输出。
- One to one结构,就是标准神经网络。
- One to many结构,仅在第一个时间步输入唯一的序列数据,接下来每一个时间步的输入都来自上一步的输出。
- Many to many并且\(T_x \not= T_y\)。则将输入时间步和输出时间步完全拆分。前半部分称之为编码器(encoder),后半部分称之为解码器(decoder)。
本节的内容参考了The Unreasonable Effectiveness of Recurrent Neural Networks
1.6- Language model and sequence generation
语言模型(Language Model) 是NLP最基本和最重要的任务,同时也是RNN极为擅长的任务。
- 什么是语言模型呢?
举个例子,下面两句话的发音是完全一样的,但当我们听到这样的语音时,更倾向于解释为听到的是第二句话,因为第二句更合理(即现实生活中,第二句的可能性远大于第一句):
The apple and ==pair== salad. The apple and ==pear== salad.
在语音识别系统内,语言模型也会告诉系统第二句的概率要大于第一句的概率。语言模型所作的内容就是,对给定一句话,计算出其概率。语言模型是语音识别和机器翻译系统的基础。
语言模型的基本任务就是,输入一句话,这句话我们用序列模型记为(这里用y而不是x表示这句话):
\[y^{\<1>},y^{\<2>},...,y^{\<T_y>}\]而语言模型将会输出这个序列单词的概率:
\[P(y^{\<1>},y^{\<2>},...,y^{\<T_y>})\]- 如何通过RNN构建语言模型
首先,需要大型语料库(corpus)组成的训练集。接着需要符号化(Tokenize),即建立词汇表,将语料库中的单词表示为one-hot向量。另外一些常见的补充做法有:额外增加专门表示句子结束的标记,称为EOS(End of Sentence);如果考虑标点符号,也会将标点符号加入词汇表并符号化;对于不在词汇表的单词全部用UNK表示。
接下来,我们就可以用RNN对序列的可能性建模了。下面,我们用如下句子举例说明:
Cats average 15 hours of sleep a day.<EOS>
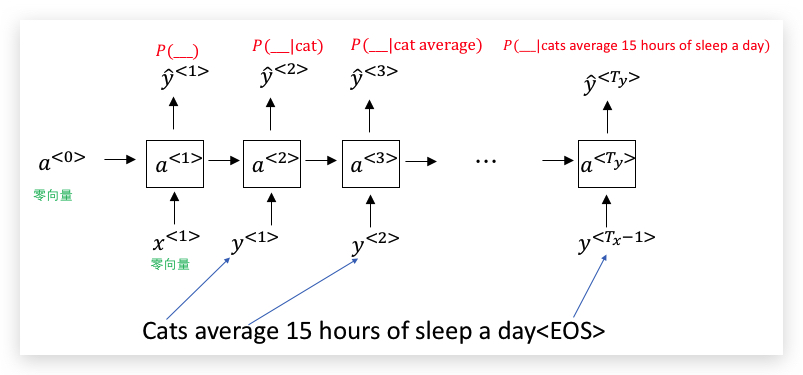
- 在\(t=0\)的时候,输入\(x^{<1>}\)和\(a^{<0>}\)都是零向量,而\(a^{<1>}\)将使用softmax预测第1个单词\(y^{<1>}\)的概率\(\hat y^{<1>}\)(注意两个符号不一样),具体来说这一步做的是用softmax预测词汇表里任何一个单词出现在句首的概率,因此这个softmax的维度和词汇表一样。在上面的例子,就是第一个单词是
cats的概率 \(P(\text{cats})\) 。 -
然后是第二步(在\(t=1\)的时候),预测第2个单词的概率,但我们会告诉模型第1个单词实际是什么,即\(x^{<2>} = y^{<1>}\),对应例子里面的 cats,而\(a^{<2>}\)将使用softmax预测第2个单词在第1个单词已经是cats下的条件概率\(\hat y^{<2>}\),在本例就是\(P(\text{average}\text{cats})\)。 -
然后是第三步(在\(t=2\)的时候),预测第3个单词的概率,并告诉模型第2个单词实际是什么,即\(x^{<3>} = y^{<2>}\),对应例子里面的 average,而\(a^{<3>}\)将使用softmax预测第3个单词在第前2个单词已经是cats average下的条件概率\(\hat y^{<3>}\),在本例就是\(P(\text{15}\text{cats average})\)。 - 以此类推。最后一个步骤(在\(t=9\)的时候),将计算\(P(\text{<EOS>}|\text{cats average 15 hours of sleep a day})\)。
上面需要注意:\(y^{<1>}\)和\(\hat y^{<1>}\)的区别,前者是表示的序列,即符号化的单词,是一个one-hot向量;后者是时间步输出的概率,是一个实数,不要混淆。
总结一下,上面的RNN学习从左到右预测,在已知前面所有单词的条件下,下一个单词的概率分布。
为了训练上面的模型,我们定义Loss Function。
首先是单独一个time step的Loss Function,其实就是softmax的Loss Function:
\[L(\hat y^{\<t>}, y^{\<t>}) = - \sum\_{i} y_i^{\<t>}\log\hat y_i^{\<t>}\](在1.4节,我们也定义过Loss Function,那是binary classification的情况)
然后将所有time step汇总,则得到整体的Loss Function:
\[L(\hat y, y) = \sum \_{t} L(\hat y^{\<t>}, y^{\<t>})\]如果用很大的训练集训练这个RNN,就可以得通过开头的单词预测之后单词的概率。比如有一个新的句子(含有三个单词:\(y^{<1>}, y^{<2>}, y^{<3>}\)),可以用模型计算出句子中各个单词的概率,然后相乘就是整个句子的概率:
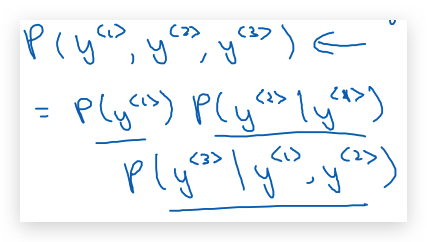
1.7- Sampling novel sequences
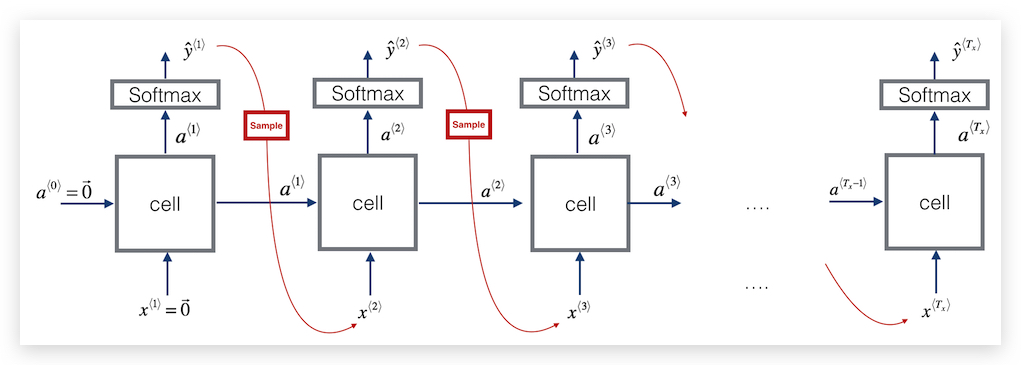
训练一个序列模型后,如何理解训练的模型到底学习到了什么?对于CNN我们介绍过其可视化方法,同样RNN我们可以通过一种叫做取样产生新序列(sample to generate novel sequences) 的方法,对RNN得到一个直观感受。
前面介绍,都是已经存在语言序列,然后依次计算各个单词的概率。而这里介绍的取样方法,事先并没有序列,而是每个时间步都根据softmax输出的概率分布,随机的取样一个单词,并作为下一个时间步的输入,继续做下一个时间步的取样,以此类推。这个感觉,就有点像输入法联想,不断的联想出下一个词,最后输出一段文字,如下图:
下面是从两个语言模型取样得到的两串文本。左边的语言模型是在新闻稿上训练的,取样结果虽然语法上并不一定正确,但有类似新闻稿口吻。右边的是在莎士比亚文集上训练产生的,感觉就像莎士比亚曾经写过诗。

截止到目前,我们构建的都是单词级别(word-level)的RNN,即词汇表里是单词。一些情况下,也可以字符级别(Character-level)的RNN,词汇表里可能是由字母、数字、标点符号等组成。在字符级别的RNN下,序列里的每个元素都是单个字符。
字符级别的优缺点:
- 优点:不存在未知字符的问题。
- 缺点:序列长度太长,训练成本高。
1.8- Vanishing gradients with RNNs
与其他深度网络一样,RNN也面临梯度消失(vanishing gradients)和梯度爆炸(exploding gradients) 的问题,尤其是梯度消失的问题,更难解决。
下面以语言模型为例说明,有如下两个句子:
The ==cat==, which already ate …., ==was== full. The ==cats==, which already ate …., ==were== full.
中间是一个很长的从句,结尾处谓语(be)的形式要根据最开始的主语(cat)的单复数决定。这说明语言中经常会有长距离的依赖。但基本的RNN对这种问题的处理效果并不好,它无法捕捉到这种长距离依赖。
这是因为,在深度网络中,输出很难通过反向传播影响到浅层。尤其是梯度消失问题,输出的变化更难关联影响到浅层。具体到上面的例子,就是模型很难做到最后的谓语根据最开始的主语单复数而变化。基本RNN更多的是相近单元施加影响。下面几节会介绍如何解决此问题。
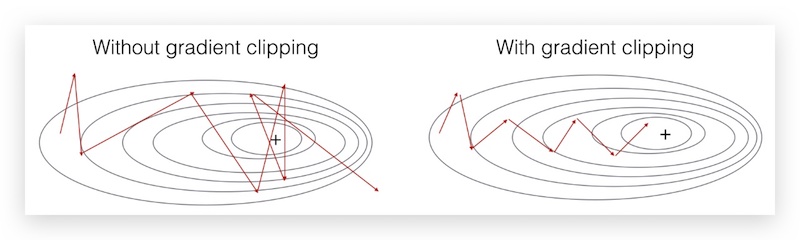
虽然梯度爆炸和梯度消失都会出现,但梯度爆炸很容易解决,比如使用梯度剪切(gradient clipping),即梯度如果超过一定阈值,则缩放梯度。相比之下,梯度消失问题要更困难。
下图是梯度剪切的效果示意:
1.9- Gated Recurrent Unit (GRU)
门控循环单元(Gated Recurrent Unit,GRU),在基本RNN单元的基础层改进,帮助RNN更好的捕捉长距离依赖和梯度消失问题。
首先,我们用画图的方式表示基本RNN单元,方便后面介绍GRU单元:
- 先介绍简化版的GRU
GRU经引入一个新的变量\(c\),作为记忆单元(Memory Cell),其作用是提供一定比特的记忆,比如上例中记忆cat是单数还是负数。在时间\(t\),记忆单元的值记为\(c^{<t>}\)。在GRU中,虽然输出的激活函数\(a^{<t>}\)总是和\(c^{<t>}\)相等,但我们还是提供两个标记区别,主要是为了和后面LSTM保持标记的统一性。
下面是GRU单元的公式:
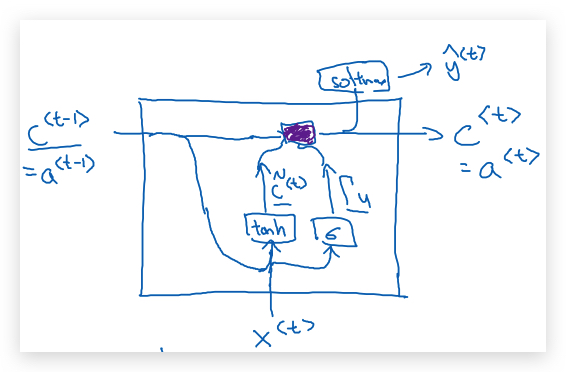
首先是\(\tilde c^{<t>}\),代表将用于替换\(c^{<t>}\)的候选(candidate)值: \(\tilde c^{\<t>} = tanh(W_c[c^{\<t-1>}, x^{\<t>}] + b_c)\)
然后是引入GRU的重要思想Gate,我们用\(\Gamma_u\)表示:
\[\Gamma_u = \sigma(W_u[c^{\<t-1>}, x^{\<t>}] + b_u)\]其中\(\Gamma_u\)的下标u表示update。激活函数\(\sigma\)使用sigmoid函数,取值0到1之间,但下面为了理解上的方便,我们总是认为\(\Gamma_u\)总是取值0或1。
接下来是GRU的关键公式。前面说\(\tilde c^{<t>}\)只是候选,是因为决定权在于\(\Gamma_u\),\(\Gamma_u\)决定了什么时候去更新\(c^{<t>}\)。对应上面的例子,这个机制可能就是,从读取到cat开始,就一直在\(c^{<t>}\)记录着主语是单数,直到遇到谓语was,\(\Gamma_u\)认为就没必要再记录下去了,即开始更新\(c^{<t>}\)。具体到公式上就是:
\[c^{\<t>} = \Gamma_u \times \tilde c^{\<t>} + (1-\Gamma_u) \times c^{\<t-1>}\]上式中乘法是elment-wise的。假如\(\Gamma_u = 0\),则表示保持记忆不变,即\(c^{<t>} = c^{<t-1>}\) ;假如\(\Gamma_u = 1\),则表示更新记忆,即\(c^{<t>} = \tilde c^{<t>}\) 。
对应上面记忆单复数的问题,可以表示如下,中间的单词都是\(\Gamma_u = 0\),维持记忆。
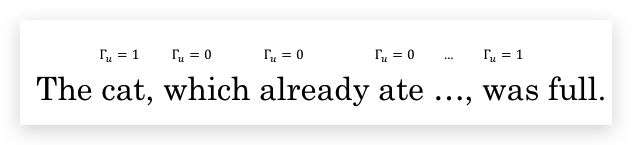
把上述GRU单元的公式,用图表示如下:
因为sigmoid很容易取值到零(只要输入到sigmoid的值是很大的负数),这些\(\Gamma_u\)大体都维持为0,也就是说\(c^{<t>}\)几乎等于\(c^{<t-1>}\) ,即虽然经过了很多时间步,\(c^{<t>} \)的值也被很好的维持了,这样有利于解决梯度消失问题(为什么?),也允许神经网络实现长距离依赖。
(上面sigmoid很容易取值为0的解释,我觉得存疑)
补充一下上面实现的细节:\(c^{<t>}\)可以是向量,比如激活函数值有100维,则\(c^{<t>}\)也是100维;相应的\(\tilde c^{<t>}\)和\(\Gamma_u\)也是向量。\(c^{<t>}\)是向量,比方说可以让某些分量表示主语的单复数,某些分量表示是吃食物还是谈论食物。
- 完整的GRU
我们先把上面简化的GRU公式整理如下:
\(\tilde c^{\<t>} = tanh(W_c[c^{\<t-1>}, x^{\<t>}] + b_c)\) \(\Gamma_u = \sigma(W_u[c^{\<t-1>}, x^{\<t>}] + b_u)\) \(c^{\<t>} = \Gamma_u \times \tilde c^{\<t>} + (1-\Gamma_u) \times c^{\<t-1>}\)
完整的GRU的差别在于,计算\(\tilde c^{<t>}\)的公式,对\(c^{<t-1>}\)加了一个相关门(Relevance Gate)\(\Gamma_r\),表示\(\tilde c^{<t>}\)和\(c^{<t-1>}\)的相关性。修改后的公式如下:
\(\tilde c^{\<t>} = tanh(W_c[ \Gamma_r \times c^{\<t-1>}, x^{\<t>}] + b_c)\) \(\Gamma_u = \sigma(W_u[c^{\<t-1>}, x^{\<t>}] + b_u)\) \(\Gamma_r = \sigma(W_r[c^{\<t-1>}, x^{\<t>}] + b_r)\) \(c^{\<t>} = \Gamma_u \times \tilde c^{\<t>} + (1-\Gamma_u) \times c^{\<t-1>}\)
paper参考:
- Cho et al., 2014. On the properties of neural machine translation: Encoder-decoder approaches
- Chung et al., 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
1.10- Long Short Term Memory (LSTM)
LSTM可以看做GRU的变体,并且更强大和常用。下面是GRU和LSTM单元的公式对比

GRU的特点是:
- \(a^{<t>}\)总是和\(c^{<t>}\)相等。
- 一共有两个gate,更新门\(\Gamma_u\)和相关门\(\Gamma_r\)
- 记忆单元\(c^{<t>}\)和候选记忆单元\(\tilde c^{<t>}\)
LSTM与GRU的区别是:
- \(a^{<t>}\)和\(c^{<t>}\)不相等。
- 去掉了计算\(\tilde c^{<t>}\)所用的相关门\(\Gamma_r\)
- 由于\(a^{<t>}\)和\(c^{<t>}\)不相等,计算\(\tilde c^{<t>}\)各种门的输入也变成了\(a^{<t-1>}\)
- 为了计算\(c^{<t>}\),还引入了遗忘门(Forget Gate)\(\Gamma_f\),代替\(1- \Gamma_u\)
- 为了计算\(a^{<t>}\),引入了输出门(Output Gate)\(\Gamma_o\)
- 总结下来,LSTM有3个gate
LSTM单元可以表示为下图:
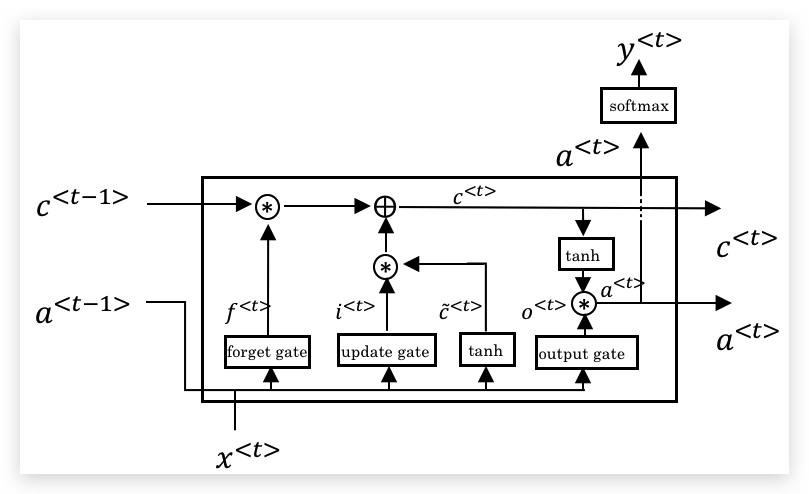
(图片主要受此博客的启发:Understanding LSTM Networks)
多个LSTM单元连在一起:
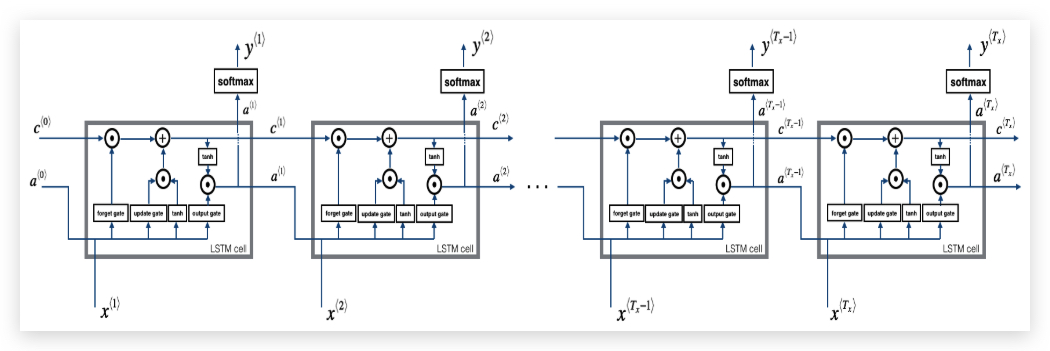
图上贯穿\(c^{<t>}\)的一条直线,就是实现长距离依赖的关键。
关于GRU和LSTM的选择: 虽然GRU比LSTM更简单,但其实GRU出现的比LSTM要晚一些,它可以看做对LSTM的简化。GRU相对LSTM的优势之一就是它更简单,适合构建更大型的网络;但LSTM更强大些。目前看来,通常会将LSTM作为默认模型测试。
paper参考:Hochreiter & Schmidhuber 1997. Long short-term memory
1.11- Bidirectional RNN
前面介绍的RNN,只能基于序列的历史数据做预测,而有些情况需要结合序列的未来数据做预测,比如前面提到的预测Teddy是否为人名的例子:
He said, “Teddy Roosevelt was a great President.” He said, “Teddy bears are on sale!”
这个时候双向RNN(Bidirectional RNN, BRNN) 是非常有效的,它可以在序列的任何位置使用到之前和之后的所有序列数据。其原理是增加了一个反向backward recurrent components
BRNN首先包含了单向RNN(可以是基本RNN、GRU或LSTM)的基本结构,如下:
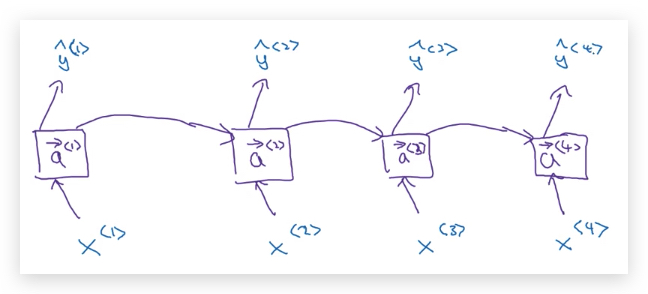
这里只包含了前向循环,因此每个时间步的激活函数都用带右箭头的\(\overrightarrow a^{<t>}\)表示。
然后,在每个时间步上添加上反向循环单元:
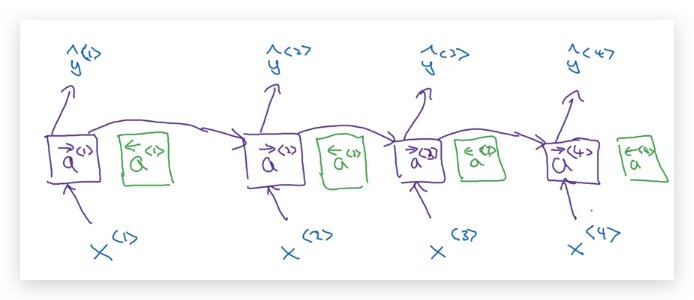
反向循环单元,也类似于前向循环单元一样,连接起来:
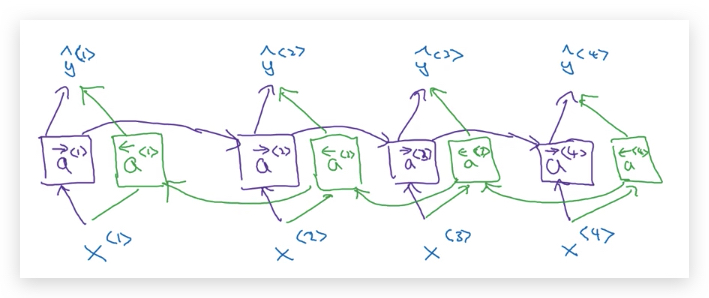
这种网络被称为非循环图(Acyclic Graph)
每个时间步的预测值计算,需要同时考虑前向激活函数\(\overrightarrow a^{<t>}\)表和反向激活函数\(\overleftarrow a^{<t>}\):
\[y^{\<t>} = g(W_y[\overrightarrow a^{\<t>}, \overleftarrow a^{\<t>}] + b_y)\]可以看出计算\(\hat y^{<1>}\)要等所有序列扫描结束后才能输出。但这也造成了一个弱点,比如语音识别,需要等用户说完一整句才开始识别,所以真正的实时语音识别,会使用更为复杂的模块,而不是仅使用标准的BRNN。
1.12- Deep RNNs
为了解决更复杂的问题,我们会将多个RNN叠在一起形成深度RNN(Deep RNN)。
下面是我们之前接触的RNN,每个RNN单元可以是基本RNN单元、GRU或LSTM:
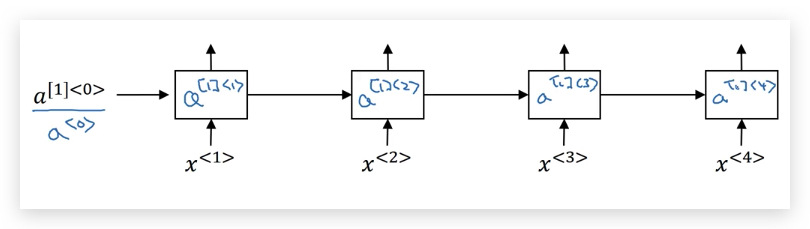
为了加以区别,在激活函数上标增加了中括号表示层数:\(a^{[l]<t>}\)表示第\(l\)层的第\(t\)个时间步的激活函数。
然后我们将多个RNN叠在一起,下面就是一个3层RNN:
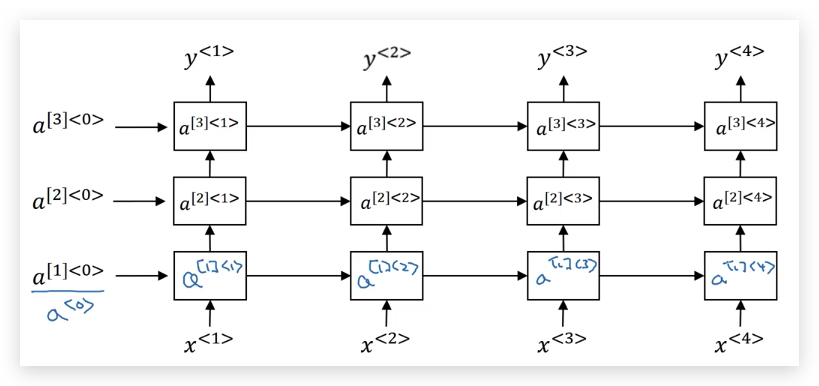
以\(a^{[2]<3>}\)为例,其输入同时来自于上一层的激活函数\(a^{[1]<3>}\)和本层上一个时间步的激活函数\(a^{[2]<2>}\),其计算公式是:
\[a^{\[2]\<3>} = g(W^{[2]}\_a [a^{\[1]\<3>}, a^{\[2]\<2>}] + b^{[2]}\_a)\]对于标准CNN来说,可以有很多层,比如100个隐藏层,但对RNN来说3层就已经很深了,因为RNN还有很长的时间维度(temporal dimension),即便3层RNN的训练难度也很大。
当然我们也可以用BRNN创建深度BRNN。
附
这一周的课程中有一个生成jazz的作业,非常有意思,下面是我根据作业生成的jazz,听起来还真像那么回事:
-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/deeplearning-ai-notes-course5-week1 欢迎指正或在下方评论。