斯坦福CS20 TensorFlow学习笔记(1):Overview of Tensorflow
1- TensorFlow是什么?
Google官方的介绍是:
TensorFlow™ is an open source software library for high performance numerical computation.
TensorFlow最早起源于Google内部的机器学习工具,而TensorFlow则是该工具于2015年11月的开源实现(剥离了Google内部代码的依赖)。
2- 为什么选TensorFlow
除TensorFlow之外,还有许多比较流行的机器学习框架,比如:
- Torch (facebook)
- Theano
- Caffe (Microsoft)
- CNTK
我们选择TensorFlow的原因是:
- 灵活性(Flexiblity)和可伸缩性(Scalablity)
-
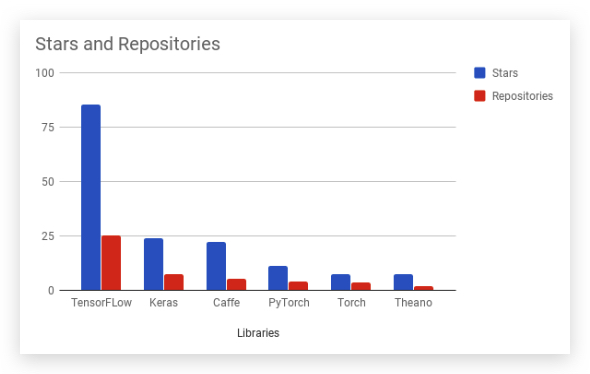
流行度(Popularity) 特别是流行度,目前TensorFlow的流行度远超其他几个框架。下图展示了GitHub上TensorFlow的start数和仓库数远大于其他框架
另外,TensorFlow还具有如下几个特性:
- Portability
- visualization:TensorBoard
- autodiff
- checkpoints
3- 课程辅助资料
TensorFlow的变化非常大,因此最好的参考资料还是官网,但CS20也推荐的一些参考资料:
- TensorFlow’s official sample models
- StackOverflow should be your first port of call in case of bug Books
- Aurélien Géron’s Hands-On Machine Learning with Scikit-Learn and TensorFlow (O’Reilly, March 2017)
- François Chollet’s Deep Learning with Python (Manning Publications, November 2017)
- Nishant Shukla’s Machine Learning with TensorFlow (Manning Publications, January 2018)
- Lieder et al.’s Learning TensorFlow A Guide to Building Deep Learning Systems (O’Reilly, August 2017)
4- Graph和Session
4.1- 计算定义与执行分离
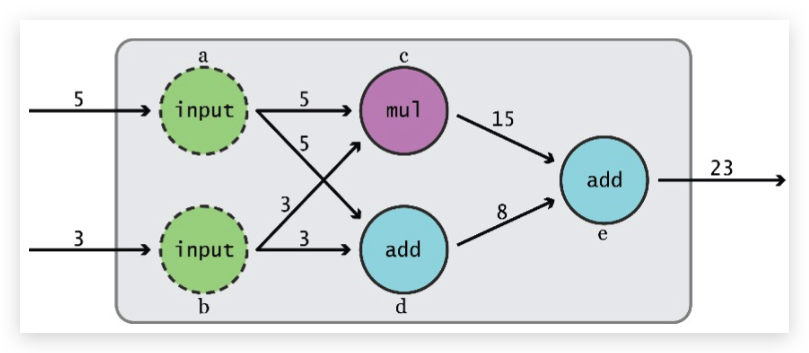
TensorFlow的重要思想是:将计算的定义和其执行相分离,这样思想也是依赖于graph和session的,即:
- 第一步:组装一个graph,即定义计算
- 第二部:使用session执行graph上的操作(operation),即执行计算。
下面是graph的一个图示:
建议通过官方文档进一步深入了解TensorFlow的核心概念,我们补充了下面几个参考:
- https://www.tensorflow.org/guide/low_level_intro
- https://www.tensorflow.org/api_docs/python/tf/Tensor
- https://www.tensorflow.org/api_guides/python/framework#Core_graph_data_structures
4.2- 什么是tensor?
个人认为,在谈tensor的时候,我们最好区别一下广义的tensor和狭义的tensor,分别理解。广义的tensor是一个数学概念,狭义的tensor是指TensorFlow框架中的tf.Tensor。
广义的tensor,一种理解是指对向量和矩阵的推广,可以理解为n维数组(An n-dimensional array),所以有:
- 0-d tensor: scalar (number)
- 1-d tensor: vector
- 2-d tensor: matrix
- and so on
在机器学习里,是借用了tensor这种数学概念,表示常常出现的多维数组。
tf.Tensor是一种Python类型,它并没有实际存储数据,技术上来说,我们直接打印一个Tensor,并不能得到tf.Tensor对应的值(或称之为tensor value,具体来说就是numpy中的ndarray,对应理解为即广义上的tensor)。而要得到tensor value,则需要通过session运行得到,接下来会介绍。
4.3- Data Flow Graphs
TensorFlow的计算过程会被表示为graph,比如:
import tensorflow as tf
a = tf.add(3, 5)
对应的graph是:
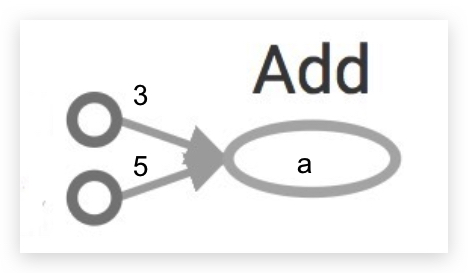
特别需要注意的是:常规的图,我们一般习惯用node表示数据,edge表示功能。在TensorFlow里恰好相反,需要适应:
- node表示的是:operators, variables, and constants(相当于flow)
- edge表示的是:tensors
若tensor理解为data,则:TensorFlow = tensor + flow = data + flow。即tensor(广义的含义)在graph中流动(flow)。
4.4- sessioin
4.4.1- How to get the value of a tensor?
tf.Tensor并不直接存储对应的tensor value。比如我们直接对一个tensor应用print,得到的是结果类似如下:
<tf.Tensor 'Add:0' shape=() dtype=int32>
因为,我们只是用tf.Tensor定义计算过程,但得到计算值,要使用session来evaluate,具体来说就是:
- 创建一个session
- 在session内,使用run方法evaluate一个graph
比如:
import tensorflow as tf
a = tf.add(3, 5)
sess = tf.Session()
print(sess.run(a))
sess.close()
session会查看graph,然后思考:嗯,我怎么得到a的值呢?为此它会计算所有通向a的node。(这里有个隐含的意思,session只计算通向a需要的部分,对于跟本次计算无关的部分不计算,下面会有例子看到。)
总结一下,一个session对象封装了一个环境,在这个环境内operation对象被执行,Tensor对象被evaluate。(A Session object encapsulates the environment in which Operation objects are executed, and Tensor objects are evaluated. )
另外,session也会为存储当前Variable的值分配内存。
4.4.2- subgraphs
之前,我们提到session指计算图中通向目标node的node们,下面加以说明。假如我们有以下代码:
x = 2
y = 3
add_op = tf.add(x, y)
mul_op = tf.multiply(x, y)
useless = tf.multiply(x, add_op)
pow_op = tf.pow(add_op, mul_op)
with tf.Session() as sess:
z = sess.run(pow_op)
计算图如下:
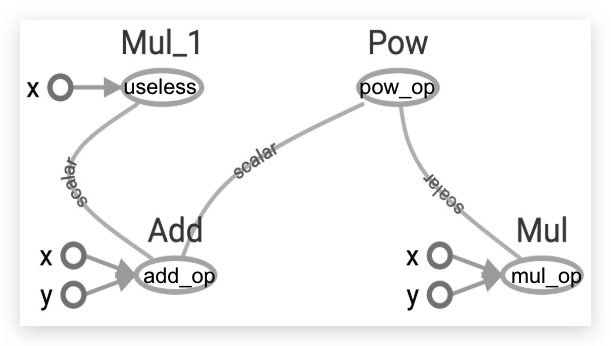
我们看到useless这个节点,对最后计算pow_op没有作用,因此实际上useless节点并没有被计算。
如果我们将pow_op和use_less都放在session.run里面,就可以一起计算了:
x = 2
y = 3
add_op = tf.add(x, y)
mul_op = tf.multiply(x, y)
useless = tf.multiply(x, add_op)
pow_op = tf.pow(add_op, mul_op)
with tf.Session() as sess:
z, not_useless = sess.run([pow_op, useless])
这里,传入run的参数是一个list。tf.Session.run的方法签名如下,其中第一个参数fetches可以是一个list:
tf.Session.run(fetches,
feed_dict=None,
options=None,
run_metadata=None)
subgraph的作用之一是做分布式计算,即将一个graph拆分为多个部分,并行的在多个GPU、CPU、TPU或其他设备上运行。比如AlexNet的第一个卷积层,就是将96个filter放在两个GPU上运算的。下图是将graph分布到两个GPU上计算的示意图:
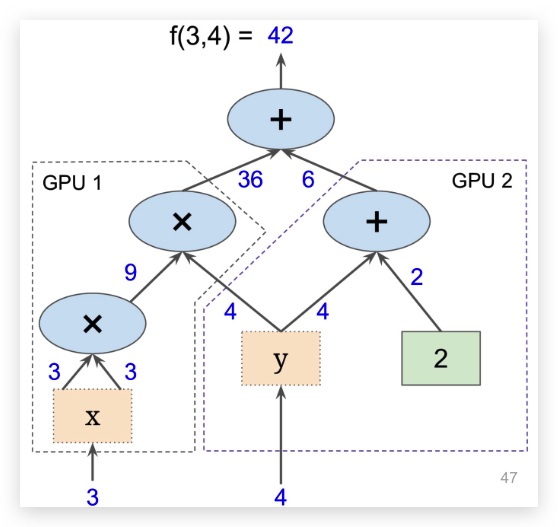
下面是TensorFlow中用tf.device指定graph部分节点在不同设备上计算的代码:
# Creates a graph.
with tf.device('/gpu:2'):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name='b')
c = tf.multiply(a, b)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(c))
4.5- multi graph
上面介绍的代码中,并没有显式的出现graph对象。事实上session会我们创建一个默认的graph,通常这已经足够了。但TensorFlow里是可以创建多个graph的,不过使用多个graph,下面几点是必须了解的:
- Multiple graphs require multiple sessions, each will try to use all available resources by default
- Can’t pass data between them without passing them through python/numpy, which doesn’t work in distributed
- It’s better to have disconnected subgraphs within one graph
下面总结了graph的一些API:
创建graph的方法是:
tf.graph()
创建graph后,可以在graph上增加操作,前提是将其设置为默认graph:
g = tf.Graph()
with g.as_default():
x = tf.add(3, 5)
sess = tf.Session(graph=g)
with tf.Session() as sess:
sess.run(x)
获取当前默认的graph:
g = tf.get_default_graph()
不要将默认graph和用户定义graph混淆,比如下面分别在两个graph上定义了操作,如果不注意可能混淆:
g = tf.Graph()
# add ops to the default graph
a = tf.constant(3)
# add ops to the user created graph
with g.as_default():
b = tf.constant(5)
下面的写法会更清晰些:
g1 = tf.get_default_graph()
g2 = tf.Graph()
# add ops to the default graph
with g1.as_default():
a = tf.Constant(3)
# add ops to the user created graph
with g2.as_default():
b = tf.Constant(5)
最后说明一下,即便如此,还是不推荐使用多个graph。
4.6- Why graphs
TensorFlow为什么要使用graph呢?主要有如下几点:
- Save computation. Only run subgraphs that lead to the values you want to fetch.
- Break computation into small, differential pieces to facilitate auto-differentiation
- Facilitate distributed computation, spread the work across multiple CPUs, GPUs, TPUs, or other devices
- Many common machine learning models are taught and visualized as directed graphs
我个人理解,第2点的自动求导是最重要的。只有得到了计算图,才有可能实现自动求导,进而自动做反向传播,这也是机器学习框架的重要功能。
-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/cs20-tensorflow-notes-1 欢迎指正或在下方评论。
毛帅
{Code, Thoughts, Sharing}