deeplearning.ai深度学习笔记(Course4 Week2):Deep convolutional models: case studies
本周主要包含两部分:
- CNN模型案例研究:LeNet-5、AlexNet、VGG-16、ResNets、1x1 CONV、Inception Network。
- CNN的实践建议:迁移学习、数据增强。
1- Case studies
1.1- Why look at case studies?
通过学习案例,建立起对CNN网络的直觉理解。在计算机视觉上适用于一个任务的Neural Network Architecture通常也适用于另外一个任务。并且计算机视觉领域的思想,也可以应用到其他领域。
接下来将要讲解的Neural Network:
- 经典网络:
- LeNet-5
- AlexNet
- VGG
- ResNet:152层的网络
- Inception
1.2- Classic Networks
- LeNet-5
1998年发表,用来识别32x32大小的灰度手写数字,架构如下:
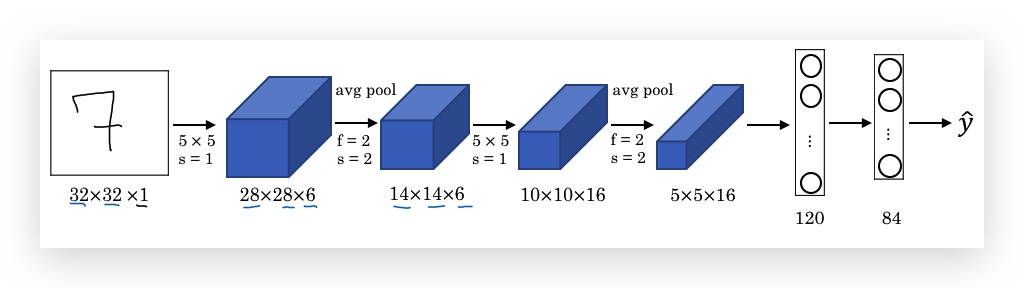
- Height和Weight不断减小,channel在增加。
- 拥有60k个参数,而今天的Neural Network通常有10M到100M个参数。
- 该模型的经典架构到现在还是很常见,即:Conv Layer紧跟着Pooling Layer,最后有多个FC layer。
LeNet-5现代的改进:
- 现代方法使用Max pooling代替原来的Average pooling
- 现代方法隐藏层non-linear激活函数,使用ReLU代替了原来的sigmoid或tanh
- 原始模型的non-linear激活函数,放在pooling之后
- 现代方法会使用softmax代替多个classifier
paper参考:LeCun et al., 1998. Gradient-based learning applied to document recognition
paper阅读: 主要看section 2,论文中有些细节是为了处理当时计算力不足的问题,现在已经不是问题,不用深究。
- AlexNet
2012年发表,以 Alex Krizhevsky 命名,作者还包括Geoffrey Hinton。架构如下:
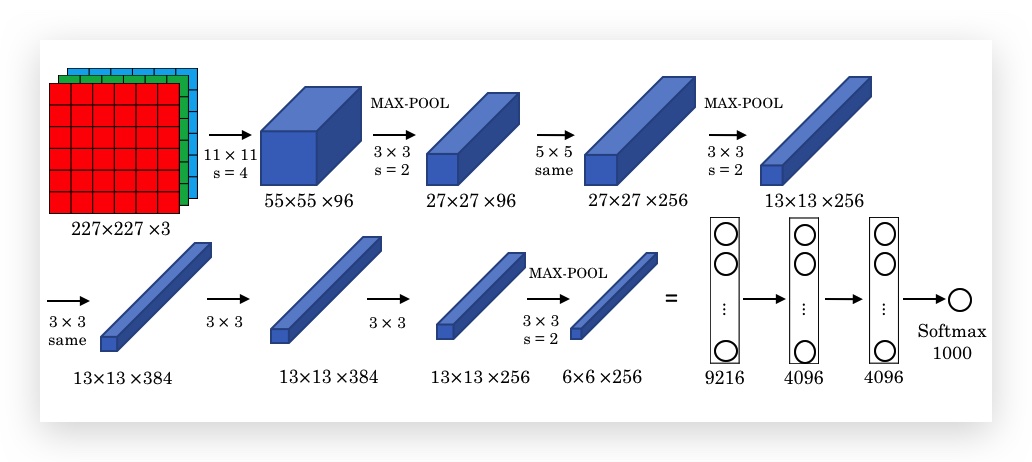
- 目标是将ImageNet图片做1000个分类
- 与LeNet-5类似,但拥有60M个参数
- 使用ReLU作为激活函数
- 让人们正式认识到deep learning在计算机视觉上的作用,不仅如此,还对计算机视觉意外的领域有深远影响。
paper参考:Krizhevsky et al., 2012. ImageNet classification with deep convolutional neural networks
paper阅读:
- 由于GPU比较慢,论文里有如何在两个GPU上运行的处理。
- 使用了Local Response Normalization(目前已不常用 )
- VGG-16
2015年发表,架构如下:
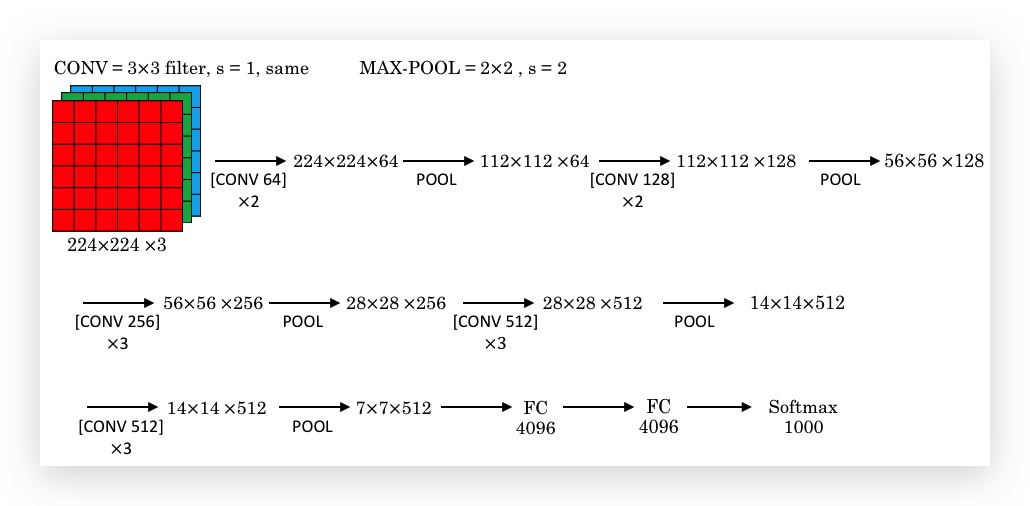
- VGG-16中16的含义是16个有参数的layer。
- 只有两个典型单元(CONV=3×3filter, s=1, same;MAX-POOL=2×2, s=2),超参较少,简化了神经网络的架构,设计上和很规律:Height不断减倍,而filter不断加倍。
- 若干个Conv Layer后跟着一个Pooling Layer。
- 参数达136M。
paper参考:Simonyan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition
衍生版:VGG-19,网络更大,但提升不大,因此VGG-16更常用。
三篇paper的阅读顺序建议:AlexNet ==> VGG-16 ==> LeNet-5
1.3- ResNets
超大型深度神经难以训练,因为会出现梯度消失和梯度爆炸问题(vanishing and exploding gradient),导致训练超大型神经网络非常困难。在反向传播的过程中,越是前层网络,叠加相乘的权重越多,因此越是前层网络的梯度消失现象越严重(极少情况下,也为出现严重的梯度爆炸)。下图显示,不同层的梯度下降的速度,越是前层下降越看。
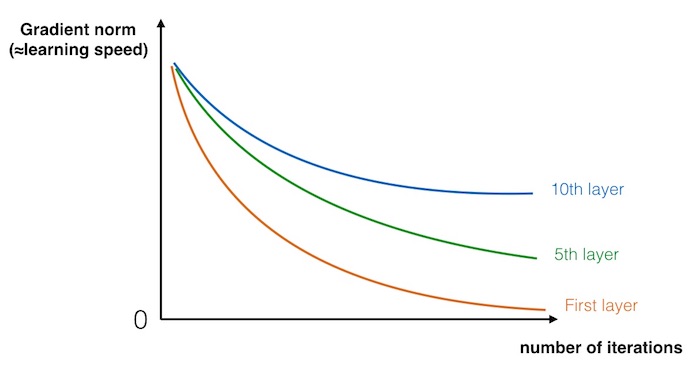
ResNets(Residual Network)使用short cut的方法(也称skip connection),解决了训练超大型Neural Network的问题。
- Residual block与Residual Network
下图是一个一般的Neural Network(相对于ResNets,也称为Plain Network)
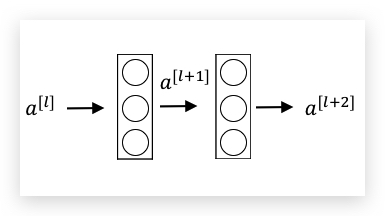
forward计算过程是一层接着一层顺序的进行,ResNets称之为Main Path,即是:
\(a^{[l]}\) ==> Linear计算 ==> ReLU ==> \(a^{[l+1]}\) ==> Linear计算 ==> ReLU ==> \(a^{[l+2]}\)
计算表达式则为:
\(z^{[l+1]} = W^{[l+1]} a^{[l]} + b^{[l+1]}\) \(a^{[l+1]} = g(z^{[l+1]})\) \(z^{[l+2]} = W^{[l+2]} a^{[l+1]} + b^{[l+2]}\) \(a^{[l+2]} = g(z^{[l+2]})\)
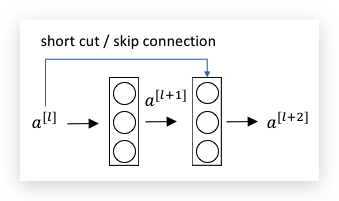
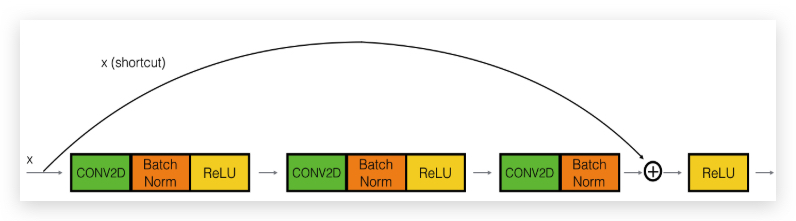
Residual block,则是在Main Path之外,将\(a^{[l]}\)的值直接加入到\(a^{[l+2]}\)的运算中,即\(a^{[l+2]} = g(z^{[l+2]}+a^{[l]})\) , 称之为short cut或skip connection,如下图:
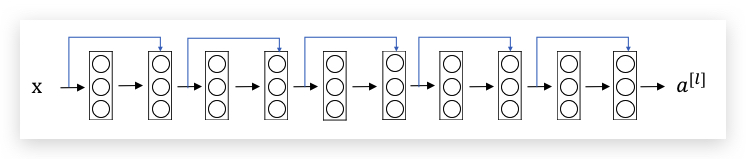
上面包含short cut的layer在一起组成了一个Residual block,多个Residual Block则构成了ResNets,如下图,是一个ResNet,共有5个Residual block:
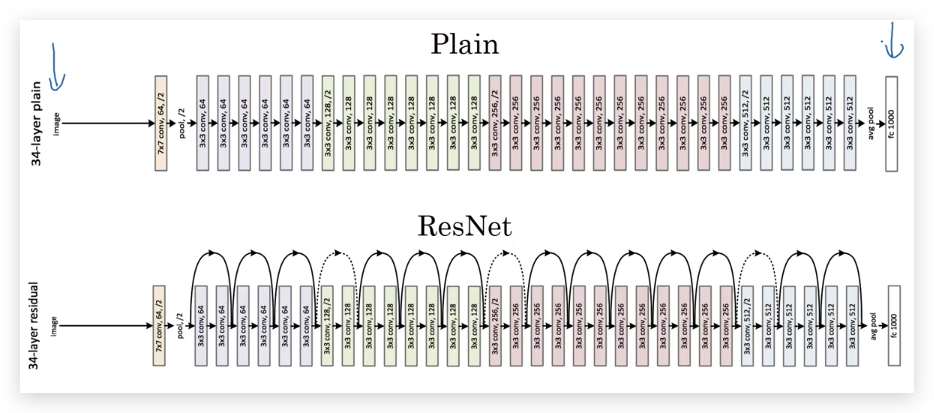
- ResNet vs Plain Network
理论上,随着layer的增加,Neural Network的Training error的趋势是降低;但现实情况是,Plain Network会先下降再上升,而ResNet则不会出现这种情况。所以会形成下面的趋势图:
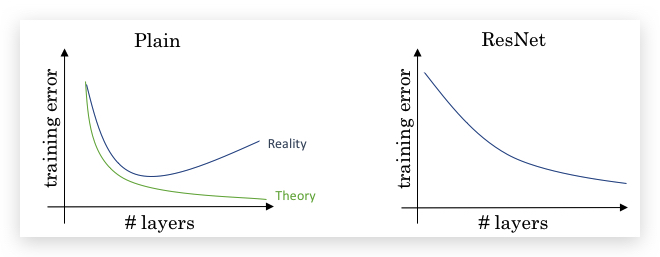
因此即便训练几百层甚至上千层的Neural Network,ResNet依然不会出现Training Error上升的情况。相比Plain Network,ResNet可以训练更多层的神经网络。
Paper参考:He et al., 2015. Deep residual networks for image recognition
1.4- Why ResNets Work
看一个例子,对于一个大型Neural Network如下:
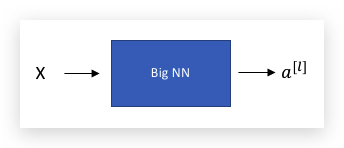
在此基础上,增加一个Residual block,如下:
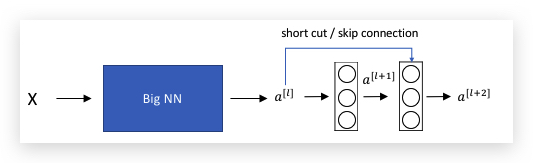
则有:
\[\begin{equation} \begin{split} a^{[l+2]} &= g(z^{[l+2]}+a^{[l]}) \\\\ &= g(W^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]}) \end{split} \end{equation}\]如果使用L2 Regularization,则\(W^{[l+2]}\)趋近于0,如果也假设\(b^{[l+2]}\)为0,并且激活函数是ReLU,则有
\[a^{[l+2]} = g(a^{[l]}) = ReLU(a^{[l]})= a^{[l]}\]也就是说ResNets很容易学习到一个等效函数,相当于Residual Block不起作用。但如果\(W^{[l+2]}\)没有趋近于0,则又可以保留更多的网络,实现网络更复杂的Non-linearity。
即shortcut允许梯度直接反向传播到前层网络。
(注:说实话这个解释我感觉有点牵强,以后有机会再理解理解。或者是不是可以这样理解:ResNet可以让算法自己弹性的选择网络的实际深度, 某种角度看,相当于把层数这个超参交给了网络自己学习)
另外,一般我们假设\(z^{[l+2]}\)如果和\(a^{[l]}\)的维度一样,所以经常是和“SAME”卷积一起使用。 如果维度不同(一般是\(z^{[l+2]}\)维度较大),则增加一个\(W_s\)矩阵调整\(a^{[l]}\)为\(W_s a^{[l]}\),其中\(W_s\)可以是一个需要学习的参数;或者仅仅将\(a^{[l]}\) padding补零。
下图是ResNet论文中将一个Plain Network转换成ResNet的例子:
下面是作业中的例子:
这里的short cut也跨越了3层。
1.5- Networks in Networks and 1x1 Convolutions
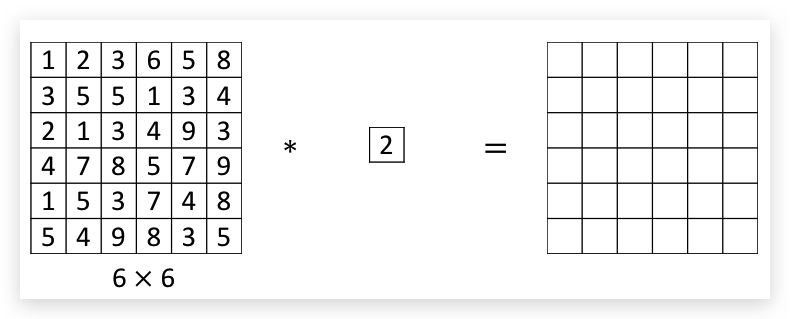
1x1 指的是filter的维度是1x1,下图是一个6x6的矩阵和一个1x1的filter做卷积,显然结果矩阵仅相当于将输入矩阵每个元素乘以2,并没有什么实质用途:
但矩阵和filter如果有多个channel,则情况有所不同:
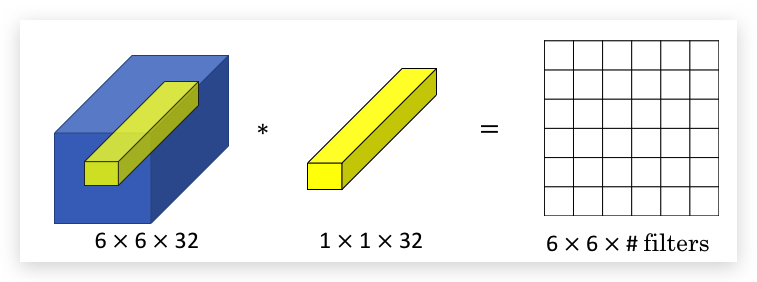
此时,1x1 Convolutions相当于在channel之间形成FC:即输入矩阵每个位置的元素在filter之间组成了一个向量(上图蓝色volume中的黄色部分),和多层channel的1x1 filter(实际上也是一个向量)做线性组合,再将结果应用激活函数(如ReLU),这个操作过程和一般NN中的一层是一样的。因此,1x1 Convolutions也称为Network in Networks。如果有多个1x1 Convolutions,则输出矩阵也是多个channel的。
从本质上看,1x1 Convolutions并没有什么特别,不过是filter维度为1x1的这种特殊情况。
1x1 Convolutions的效果:
- 在不改变矩阵维度的情况下,增加、减少或不改变channel的数量
- 增加了Non-linearity
1x1 Covolutions的理念有很大影响力,比如Inception Network都受到其影响。
paper参考:Lin et al., 2013. Network in network
1.6- Inception Network Motivation
- Inception network的目的
在设计ConvNet时,你可能需要手工决定用多大的filter以及是否需要pooling layer,而Inception Network则很简单粗暴:纠结什么,为何不把各种大小的filter都做一遍,并把结果连接在一起。
下图显示了,在一个layer里同时应用了1x1, 3x3, 5x5的filter以及Max Pooling,然后把所有结果堆在一起:
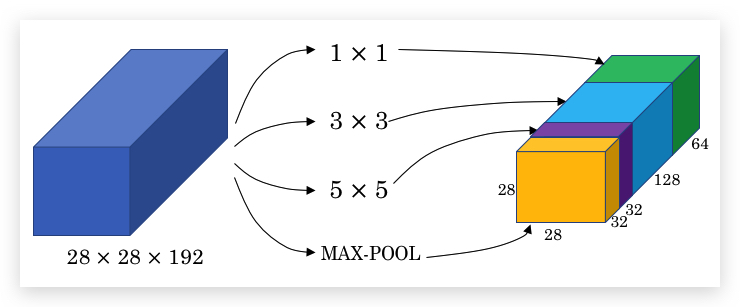
主要思想是:与其从众多filter中选择一个,不如将所有的filter都加入,并将输出连接在一起,让网络自己学习用应该哪些filter。某种角度看,相当于把filter size这个超参交给网络自己学习。
paper参考:Szegedy et al. 2014. Going deeper with convolutions
- 计算量问题
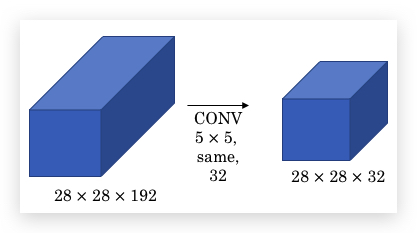
Inception network带来的一个问题是,大幅增加计算量。仅以上面例子中3x3 filter部分计算,计算乘法的次数达到:28x28x32x5x5x192,大概为120M:
- 1x1 convolution降低计算量
但如果在上面的例子中间加一层1x1 Convolution(下图黄色部分),则计算量可以显著下降:
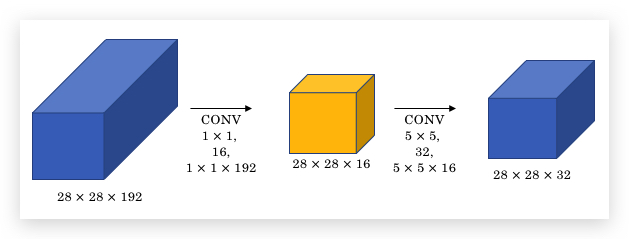
同样最后输出28x28x32的volume,但计算量是:28x28x16x1x1x192 + 28x28x32x5x5x16,算下来大概10M,相比原先120M,降低了10倍左右。
这主要是因为,通过1x1 Convolution,将原始的192的channel上缩小到16。正因为如此,1x1 Convolution层也称作bootleneck layer。
本节总结:
- 如果你不想决定Neural Network的一个layer应该用1x1、3x3、5x5还是pooling layer,可以用inception module。
- 通过1x1 Convolution创建一个bottleneck layer,大幅降低运算量,且基本不影响Network的性能。
1.7- Inception Network
上面已介绍了构建Inception Network基本要素,现在可以构建一个完整的Inception Network了。
- Inception Module
将1x1 Convolution和Inception结合在一起形成如下网络:
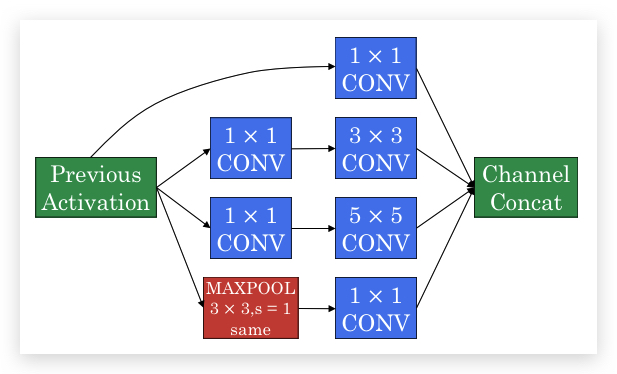
- 一般的CONV layer一般在前面增加一个1x1 CONV,降低计算量
- Max Pooling要使用SAME CONV保证维度一致,并在之后使用1x1 CONV降低channel
- 最终将所有输出的channel全部Concat在一起
- Inception Network
Inception Network,即将Inception Module重复多次。形成如下的形式:
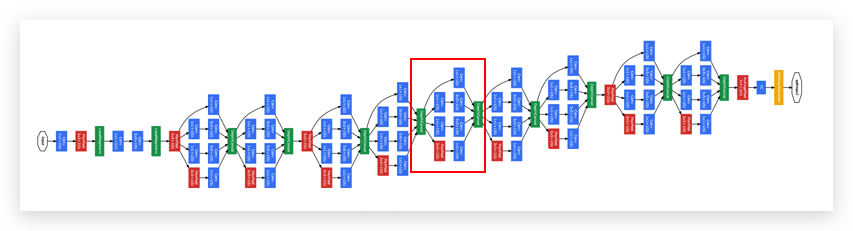
- 比如红框里面圈出的就是一个Inception Block。
- 最后几层还是FC layer加softmax layer
另外,在中间的隐藏层,还会引出几个FC layer加softmax layer,称之为side-branches,使用隐藏层直接做预测,比如下图。
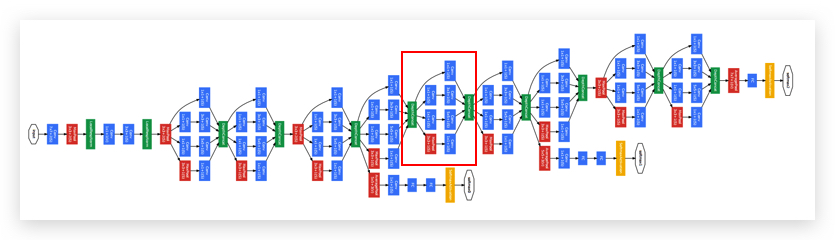
Side-branches,在预测输出上表现也不差;同时还能起到regularization的作用,抑制overfitting。
上面的Inception Network由Google的作者创立,因此也叫GoogleNet(致敬LeNet)。
Inception Network也发展出了很多版本,比如结合Skip Connection。
另外,为什么取名叫“Inception Network”?Inception的paper也做了说明,是取自电影《盗梦空间》(Inception)的梗(meme),意味 We need to go deeper(http://knowyourmeme.com/memes/we-need-to-go-deeper)

2- Practical advices for using ConvnNets
2.1- Using Open-Source Implementation
直接参考论文自己实现复杂的ConvNets并不容易,涉及到很多细节,例如超参的选择,都会影响效果。即便对顶级的AI专家或PhD也不容易。因此,在实践中推荐使用高手写好的开源实现。
2.2- Transfer Learning
构建computer vision任务,通常并不推荐从头开始训练(即random initialization),而是建议使用别人已经训练好的网络架构和参数,把这些参数当成pre-training,transfer到你要做的新任务上,这样会快很多。
Computer Vision社区,也有不少共享的data sets,比如:
- Image Net
- MS COCO
- Pascal types of date sets
举例:如果要训练算法,识别自己的两只宠物猫(一直叫Tigger,一只叫Misty),很可能你并没有很多Tigger和Misty的照片,直接训练的效果会很差。可以这样做:
- 先下载一个图片识别的开源实现,包括已训练好的参数。 比如从ImageNet下载一个可以识别1000种图片的开源实现。
- 我们只要将网络的最后一层1000维的softmarx去掉,替换成自己需要的3维的softmax(分别输出Tigger, Misty或None)
- 冻结所有layer的参数不变(freeze),只训练新的softmax layer的参数。这样即便在小数据下也能获得不错的训练效果。
| 幸运的是,很多deep learning框架,也支持这种冻结部分参数的学习方式。(我的理解:这个transfer的过程就像一个换头手术-_- | ) |
由于参数被冻结了,因此可以做一个缓存。即首先把所有图片都输入到网络,并计算出到softmax之前的activation,即图片到最后一个activation的映射,这样以后训练softmax就不用重复计算很长的网络了。
| 当然,如果拥有的training set够大,也可以少冻结一些layer的参数,训练最后几层,或者重新设计最后几层的结构。(我的理解:相当于头和上半身都换称自己的 -_- | ) |
如果training set非常大,也可以不冻结任何参数,仅用别人已训练的参数做初始化。
总结:在所有deep learning的应用中,Computer Vision是特别适合transfer learning的,没有特别原因,一般都会使用。
2.3- Data Augmentation
Data Augmentation是增加训练数据的一种方法。下面介绍几种Data Augmentation的方法。
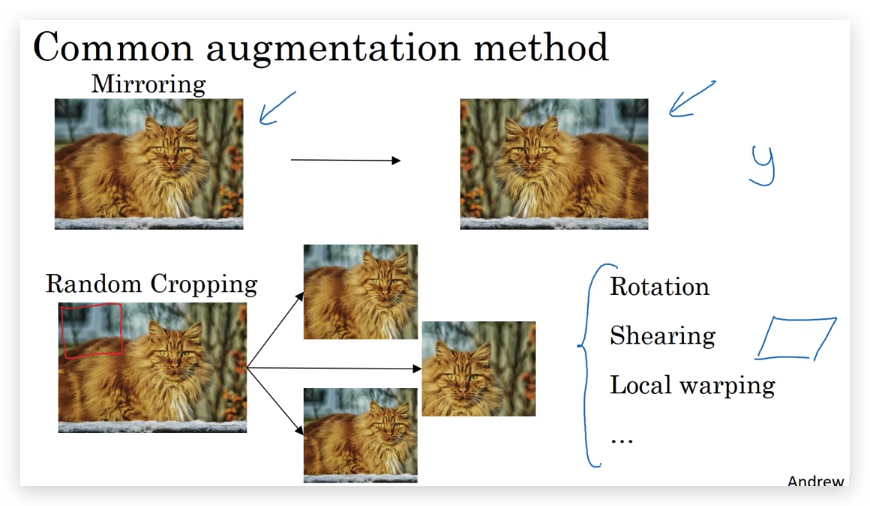
- 常见的Augmentation方法有:
- Mirroring
- Random Cropping(但并不总是一个完美的方法,因为有时裁剪的地方可能是其他对象,比如裁剪到了背景)
另外,还有:
- Rotation
- Shearing
- Local warping
- Color shifting
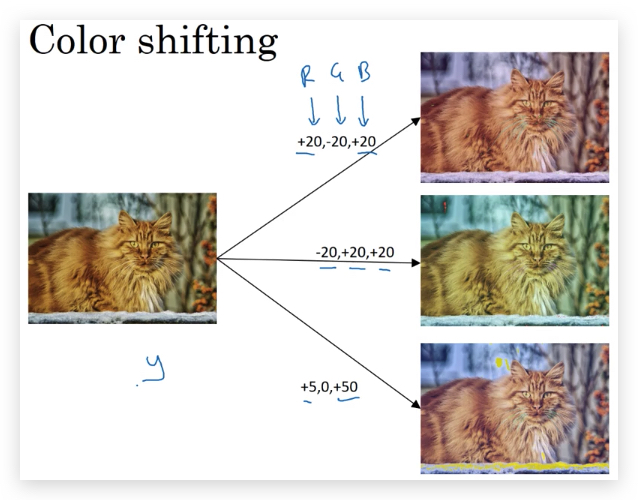
关于Color shifting,有一种更复杂的办法是PCA Color Augmentation(在AlexNet中有介绍)
- Implementating distortions during training
通常,我们会有一个线程去读取图片,并做Data Augmentation,然后再将数据输入NN进行训练。在实践中,Data Augmentation和真正的训练应该并行处理。
- 另外,Data Augmentation也引入了些超参,比如Color shifting的力度,random cropping的参数。
2.4- State of Computer Vision
- Data vs. hand-engineering
手工工程(hand-engineering或hack),是指人为精心的设计特征、神经网络架构或其他系统组件。
数据量越大,用的算法也更简单,hand-engineering或hack的成分更少;相反数据不足的情况下,hand-engineering或hack的成分更大,也更有效。即形成了下面的特点:
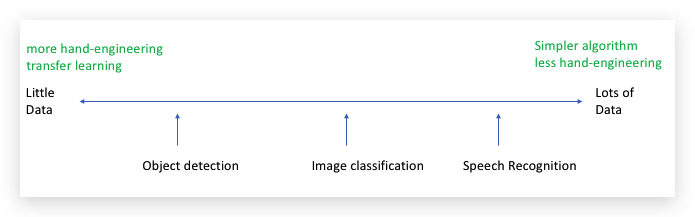
Computer vision的数据集还是相对较小,特别是Computer Vision还需要训练出一个相当复杂的函数。尤其是Object Detection,标注成本很大,因此数据集更小。因此,直到现在,Computer Vision还需要很多hand-engineering。
但也不是贬低hand-engineering,在没有足够数据的情况,hand-engineering是一项非常困难、技巧性的、需要经验的工作。
机器学习知识的两大来源:
- Labeled Data
- Hand engineered features/network architecture/other components
- Tips for doing well on benchmarks/Winning competitions
- Ensembling 即独立的训练多个神经网络,然后取所有网络的平均值。(相当于专家会诊)
- Multi-crop at test time 将Data Augmentation应用到测试集,对结果进行平均。
但这些针对竞赛的优化手段,需要更多的内存或运行时间,一般不适用与生产系统。
- 使用开源代码
- 使用已发表的论文里的网络架构
- 尽可能的使用开源实现
- 使用预训练(pretrained)好的模型,再用自己的数据调优(fine-tune)
3- Assignment
- 作业中介绍了Keras框架,Keras框架是一个高层神经网络API,建立在TensorFlow和CNTK之上。
- Keras特别适合做神经网络的原型设计,就像搭积木一样。快速尝试不同的网络架构
- Keras的编码流程:Create->Compile->Fit/Train->Evaluate/Test
-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/deeplearning-ai-notes-course4-week2 欢迎指正或在下方评论。
毛帅
{Code, Thoughts, Sharing}