deeplearning.ai深度学习笔记(Course4 Week3):Object detection
本周介绍了目标检测算法,包括使用bounding box定位,sliding window算法以及YOLO算法。其中YOLO算法涉及IoU、Non-max Suppression、Anchor Boxes。
1- Detection Algorithm
目标检测(Object detection),在近几年发展的很迅猛。目标检测的第一步是目标定位(Object Localization)
图形识别相关的问题可以分为下面三个层次:
- Image Classification:判断图片中是否包含某物。
- Classification with localization:判断图片是否包含某物,以及某物的边框。
- Detection:图片中包含多个属于不同类别的对象,识别出包含的所有对象,以及其边框。
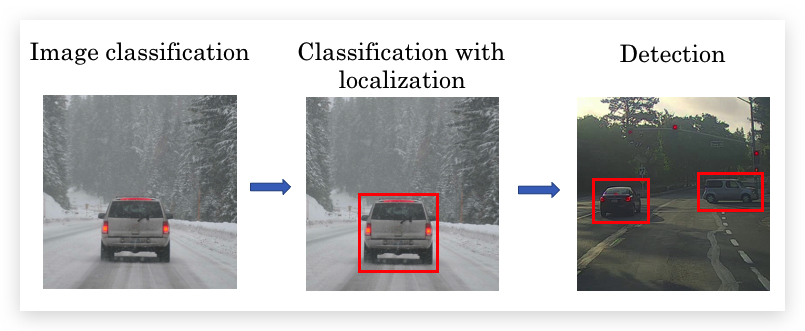
其中前两个问题通常在图片中央有一个目标对象。
本周学习的是第二个问题。
1.1- Object Localization
根据定位目标的个数,可以分为单物体定位(1 Object Localization)和多物体定位(Multiple Objects Localization)。本周先研究前者,即Classification with localization。
- bounding box
目标的具体位置,可以用边框(bounding box) 来表示, bounding box即一个定位物体的矩形框,如下图:

框住汽车的bounding box可以用四个数字表示:
- \(b_x\): 物体中心点的x坐标
- \(b_y\): 物体中心点的y坐标
- \(b_h\): 矩形框的高度
- \(b_w\): 矩形框的宽度
其中坐标系一般选择左上角为原点,右下角为(1,1),如下图:
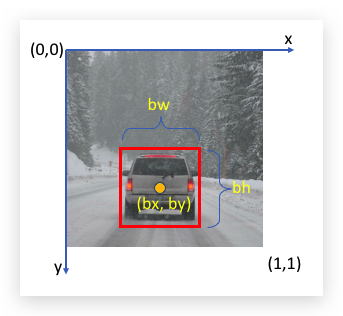
上图可能的值是\(b_x=0.5\), \(b_y=0.7\), \(b_w=0.4\), \(b_h=0.3\)。
- Classification with localization
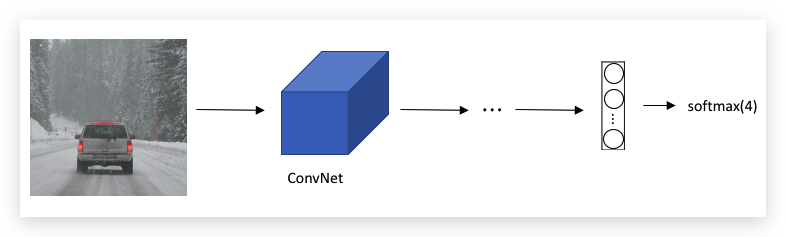
Classification问题,最终通过softmax输出one-hot向量,表示属于哪个类型的对象,比如一个路面识别四种类型(1-行人 2-车辆 3-摩托车 4-背景)的Classification的卷积网络如下:
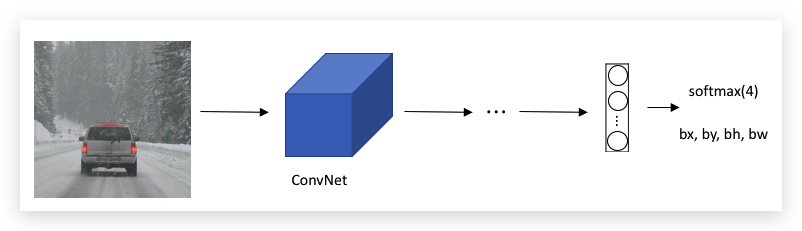
Classification with localization则在上述基础上,增加bounding box坐标的输出:
- Defining the target label y
在classification问题,只用定义一个one-hot向量,表示某个物体是否存在,而物体定位,需要在此基础上扩充为:
- \(p_c\): 表示物体是否存在
- bounding box的四个参数:\(b_x, b_y, b_h, b_w\)
- 物体分类的one-hot向量
比如上面的路面识别的例子,对应的标记向量y可以表示为形式: \(\\left[ \\begin{matrix} p_c \\\\ b_x \\\\ b_y \\\\ b_h \\\\ b_w \\\\ c_1 \\\\ c_2 \\\\ c_3 \\\\ c_4 \\\\ \end{matrix} \\right]\)
存在一个车辆的向量y就是:
\[\\left[ \\begin{matrix} 1 \\\\ 0.5 \\\\ 0.7 \\\\ 0.3 \\\\ 0.4 \\\\ 0 \\\\ 1 \\\\ 0 \\\\ 0 \\\\ \end{matrix} \\right]\]不存在目标的向量y:
\[\\left[ \\begin{matrix} 0 \\\\ ? \\\\ ? \\\\ ? \\\\ ? \\\\ ? \\\\ ? \\\\ ? \\\\ ? \\\\ \end{matrix} \\right]\]问号,表示这些值不需要关心。(有个疑问:实际程序中应该用什么代表问号)
- Loss function
损失函数\(L(\hat y,y)\)可以用平方误差的形式,根据\(p_c\)是否为1分别计算:
- 如果\(\hat y\)里的\(p_c=1\),则: \(L(\hat y,y)=(\hat y_1-y_1)^2+(\hat y_2-y_2)^2+\cdots+(\hat y_8-y_8)^2\)
- 如果\(\hat y\)里的\(p_c=0\)则仅需要计算\(p_c\)的偏差,其他分量不需要考虑: \(L(\hat y,y)=(\hat y_1-y_1)^2\)
上面举例时,每个分量都用平方误差计算,但实际可以每个分量使用不同的损失函数,比如\(p_c\)使用逻辑回归损失函数,分类标签使用softmax损失函数。bounding box四个分量使用平方误差。
1.2- Landmark Detection
Localization给出了bounding box的坐标,更一般的,可以让卷积网络学习识别关键点的坐标,这些关键点就是特征点(Landmark),这个过程即特征点检测(Landmark Detection)。
比如面部识别,可以输出的Landmark有:眼睛、嘴巴、鼻子等轮廓上关键点的坐标,根据需要识别的精度,调整需要输出的关键坐标点个数。

又比如肢体动作识别:

每个landmark用两个数字表示,比如\((l_{1x},l_{1y})\)表示第一个关键点的x和y坐标。
Landmark Detection的应用:面部识别、动作捕捉、AR。
需要注意的是,Landmark在所有样本里定义要保持一致,比如第1个landmark永远表示做眼外眼角的位置。
1.3- Object Detection
- Closely cropped images 假如要做的Car Detection,首先用closely cropped images(即紧贴着对象裁剪的图片)训练一个卷积网络,可以识别closely cropped images是否是汽车图片。

此卷积网络用于下面的sliding windows detection。
- Sliding windows detection
过程如下:
- 首先选取一个固定大小的矩形window,用这个window以一个步长在图片上从左到右,从上到下依次扫过。
- 每次window扫过的区域,使用之前根据closely cropped images训练好的卷积网络,识别区域内是否有目标对象。
- 不断增大window的大小,重复上面的操作。最后可能在某一个大小的window,在某个位置输出包含目标对象,这个位置的window就是目标对象的bounding box。

Sliding windows的主要缺点:
- 计算量巨大,因为要用不同大小的window,对整个图片不同位置做检测。window的大小和步长的大小选择对计算量影响也很大。
- 如果window选择的太大、步长太大,定位的精度也很差。
计算量的问题,可以通过Convolutional Implementation of Sliding Windows解决。
1.4- Convolutional Implementation of Sliding Windows
- Turning FC layer into Convolutional layer
下图中上半部分,最后两层是FC layer,输出是softmax。下半部分是将FC layer解释为Conv layer的示意。
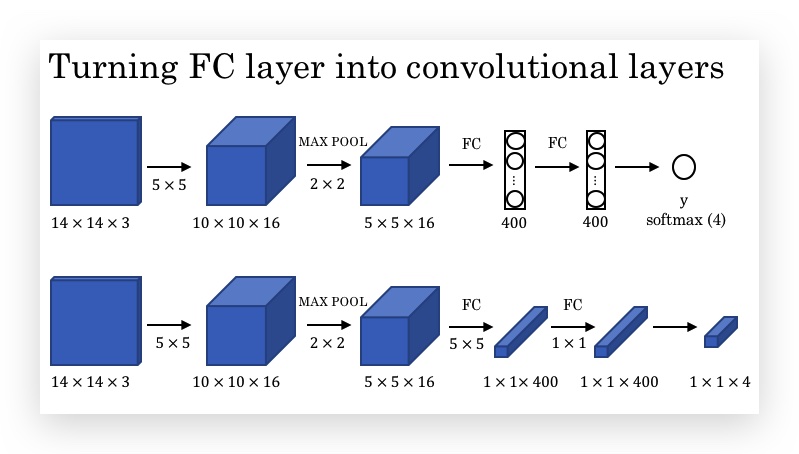
可以看出,当filter的大小和输入图片的大小一致,则ConvNet本质上就是FC。所以,这里所谓的转换成Conv Layer,只不过是观察和理解的角度不一样。
但一旦将FC转换为Conv后,有个好处是,你就不再受限于FC了,比如一旦FC前面的矩阵维度扩充了,Conv后的维度也可以跟着扩充。比如上面的输入矩阵如果改成16x16,其他参数都不变,则如下:
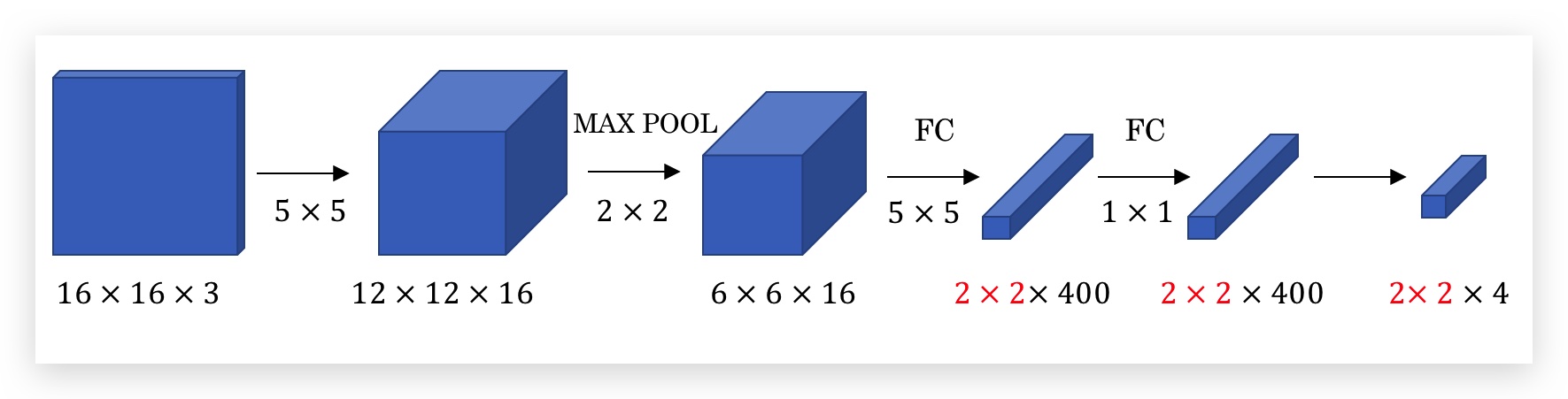
可以看出最后几层就变成了2x2的矩阵了,而FC是做不到的!下面将会用到这个特性。
- Convolutional Implementation of Sliding Windows
假如sliding window的Convnet架构如下(即用于检测closely cropped images中是否包含目标): 输入一个14x14x3的图片,输出是否包含4种类型的目标。其中最后几个FC Layer是通过ConvNet实现的。另外图中的volume只画了正面,没有画channel维度。
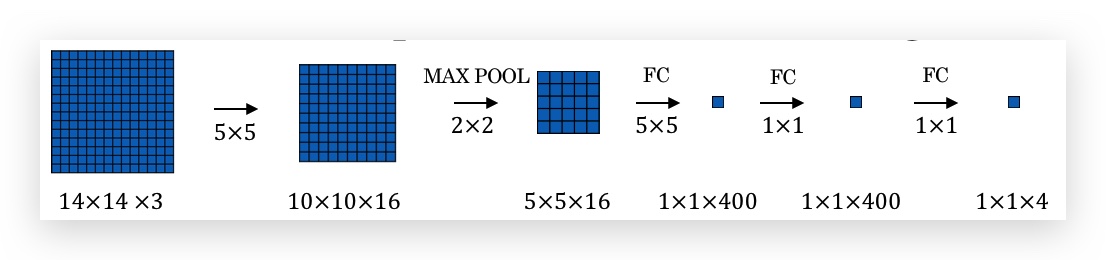
假如被测图片是一个16x16x3的图片(即要用slide window切分的,这里为了说明,维度比较小,实际上被测图片一般比slide window要大很多,黄色部分是比window大的区域),如果按步长2进行窗口滑动,一共可以滑动出4个窗口区域。
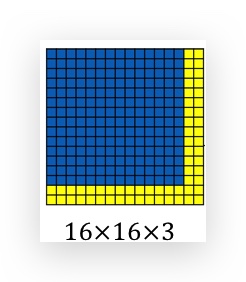
如果使用Sliding windows detection,需要切分出4个图片,分别放到ConvNet里去检测。可以看出4个window截取的区域是有重合数据的,这造成了ConvNet的4次计算有重复计算量。而Convolutional Implementation of Sliding Windows则可以共享这部分重复计算,从而大幅降低整体计算量。
具体做法是,将被测图片直接输入到sliding window的Convnet中(相同的卷积网络和参数):
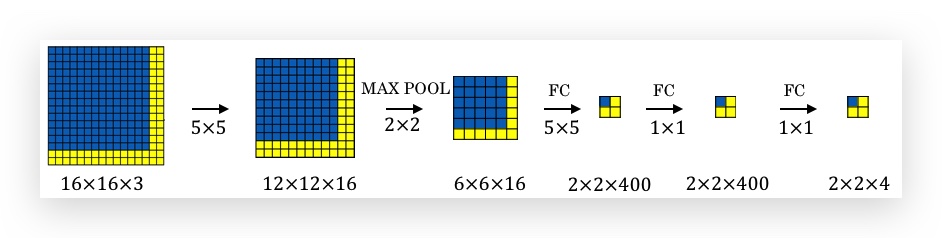
由于FC层是用ConvNet实现的,所以FC层和最后的输出会变成多维(这里是2x2),而2x2的4个数据对应的就是被测图片被sliding window切分的4个区域的预测输出。
对此,我的理解是:
- 卷积的计算,本身就是类似于slide window,不断的将filter以一个stride在原始图片上从左到右,从上到下滑动做卷积。而这个过程和单独slide好window交给Closely cropped images是一样的过程。
- ConvNet是稀疏连接的,比如2x2的输出结果,左上角的一个输出值仅受输入图片左上角14x14的区域影响。
- 由于上面的原因,一方面ConvNet帮助共享了计算,并同时参与计算,而不是像sliding window那样串行的计算,另一方面又达到了和sliding window的效果一致。
下面是更大的输入图片的例子:
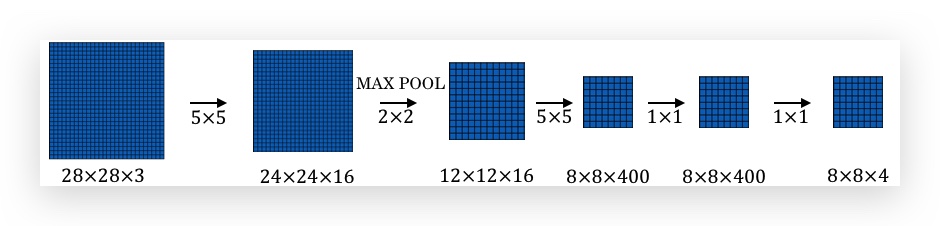
但此方法还是有一个缺点:bounding box并不准确,毕竟bounding box是由sliding window决定的。
1.5- Bounding Box Predictions
由于sliding window是固定选取的,所以识别出的bounding box可能和目标的形状实际不符,比如实际更宽或更高,或者stride比较大。一个较好的解决方法是:YOLO(You Only Look Once)算法。
- YOLO的基本过程:
- 没有sliding window,而是将图片拆分为若干个grid(比如示例中拆分为3x3,共9个grid;实际操作会拆分更多)
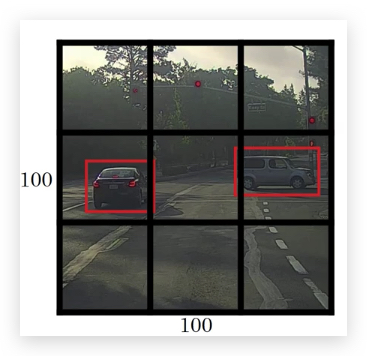
- 对每个grid应用Classification with localization算法(前面章节提到的),训练数据和算法的输出包含了目标的bounding box坐标的向量,比如: \(\\left[ \\begin{matrix} p_c \\\\ b_x \\\\ b_y \\\\ b_h \\\\ b_w \\\\ c_1 \\\\ c_2 \\\\ c_3 \\\\ \end{matrix} \\right]\)
- 一共输出9个向量(和grid个数一样)
- 没有sliding window,而是将图片拆分为若干个grid(比如示例中拆分为3x3,共9个grid;实际操作会拆分更多)
- 关于bounding box的坐标:
- 目标是否存在于grid的标准是目标的中心点是否在grid内。
- bounding box的坐标是以grid为参考的,而非整个图片。即将一个grid的左上角设置为(0,0),右下角设置为(1,1)。
- bounding box的中心点坐标\(b_x\)和\(b_y\)的值必须是0到1之间,但高度\(b_h\)和宽\(b_w\)可以是比1大,说明超过了grid(事实上不超过1也可能是在grid之外),换句话说,高度和宽度是按照物体的实际高度和宽度来算的,不受grid的限制。
- bounding box的大小不是固定的,而是直接由模型输出,模型可以以任何精度输出bounding box
- YOLO算法是卷积实现
已上面9x9个grid的例子,每个grid输出8维向量,则一共输出的是3x3x8的volume。可以设计一个这样的卷积网络: 100x100x3 ==> CONV ==> MaxPooling ==> … ==> 3x3x8
最后的3x3x8的volume,每一个1x1x8代表输入图片对应位置的grid的结果,包括是否含有目标,以及bounding box坐标和目标分类。 训练数据,也按照这个关系进行标记,放到上面的网络训练。
由于YOLO是卷积实现,并不需要根据grid拆分结果反复计算,因此计算量也会大幅减少。增加grid的数量,可降低两个物体在一个grid内的概率。
- YOLO的优点:
- 和Classification with localization类似,直接输出bounding box,不受sliding window和步长的限制,更为精确。
- 卷积实现,仅进行一次CNN正向计算,计算量降低。
我的理解:另外一个角度看,YOLO算法也颇有end-to-end learning的过程,中间并不像sliding window一样要做window的切分(这种切分更具有hand-engineering的意味)。而YOLO直接从原图片到输出在哪个grid以及具体的bounding box。
paper参考:You Only Look Once: Unified, Real-Time Object Detection Andrew Ng建议:YOLO的paper是最难的paper之一,阅读要有心理准备。
1.6- Intersection Over Union
如何检验目标检测算法给出的bounding box的效果呢?比如下图红色是汽车实际的bounding box,紫色是算法给出的bounding box,如何量化这个效果呢?

一个很自然的想法是看两个bounding box的重合度,具体可以用交集和并集的比值评判。比如下图黄色阴影部分是两个bounding box的交集(即重合部分),而绿色部分是两个bounding box的并集。IoU(Intersection Over Union)即这两个部分面积之比:
\[IoU = \frac{\text{Intersection}}{\text{Union}}\]
IoU 的值介于0到1之间,越接近1表示目标的定位越准确,IoU惯例上用>=0.5表示“正确”定位的阈值,或根据情况设置这个阈值。
1.7- Non-max Suppression
目标检测遇到的一个常见问题是:同一个目标会在多个地方检测到。而Non-max Suppression可以保证一个物体只被检测到一次。
比如用YOLO算法,将下图划分为19x19个grid,图中有两辆车,绿色点和黄色点是实际的目标中心点,但与之相邻的几个grid可能也会报告自己的\(p_c\)值很大,找到了目标。

最终检测的结果可能是如下多个bounding box(数字是检测出的\(p_c\)值):
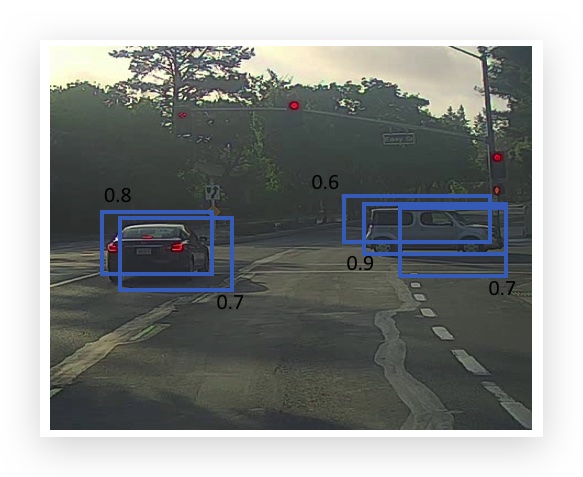
很自然的想法是,将识别了同一个物体的grid,取\(p_c\)值最大的grid。想法虽然很对,但关键点是怎么知道哪些grid识别了同一个物体呢,如上图有两个汽车,怎么将\(p_c\)值是0.8和0.9的两个grid找出?Non-max Suppression的步骤是:
- 首先丢弃所有\(p_c\)值小于0.6(该阈值可调整)的grid。(\(p_c\)太小的,很可能是识别了一些边边角角,可以直接丢弃)
- 对于所有剩余的grid
- 选取\(p_c\)值最大的grid A作为输出,即从剩余grid拿掉。
- 丢弃所有与A的IoU大于等于0.5(该阈值可调整)的grid。(这些很可能是与A相邻的,识别了同一个对象)
- 重复第2步,直到没有剩余的grid为止。
把这个算法应用到上图两量汽车的例子:
- 丢弃小于0.6的grid,这里没有要丢弃的
- 选取最大的0.9的grid作为第一个目标的输出,并且将与其bounding box的IoU超过0.5的两个grid(即右边的两个0.6和0.7的)剔除。
- 接下来再看剩余grid(只有左边0.7和0.8两个)里\(p_c\)值最大的grid,显然是0.8的grid,将其作为第二个目标的输出。0.7与其IoU超过0.5,被剔除。
- 已无剩余的grid,并输出了两个目标的grid。
non-max的意思就是输出最大可能性的grid,并抑制与其有重叠的非最大值grid
上述步骤只是对单个类别的目标检测,如果有多个类型的目标,则按每个类型分别做Non-max Suppression。
1.8- Anchor Boxes
到目前,我们的算法中一个grid只能检测一个物体,如果要想在一个grid里检测多个物体怎么办?比如下图,汽车和人的中心点是重合的。

根据之前定义的输出向量y,算法在此gird输出目标类型的时候只能选择一种。
\[\\left[ \\begin{matrix} p_c \\\\ b_x \\\\ b_y \\\\ b_h \\\\ b_w \\\\ c_1 \\\\ c_2 \\\\ c_3 \\\\ \end{matrix} \\right]\]Anchor Boxes的思想是,预定义两个形状不同的称作Anchor Box的矩形。 将要预测的两个对象分别关联到两个Anchor Box上。(实践中,会定义多个Anchor Box,这里只用2个作说明 )
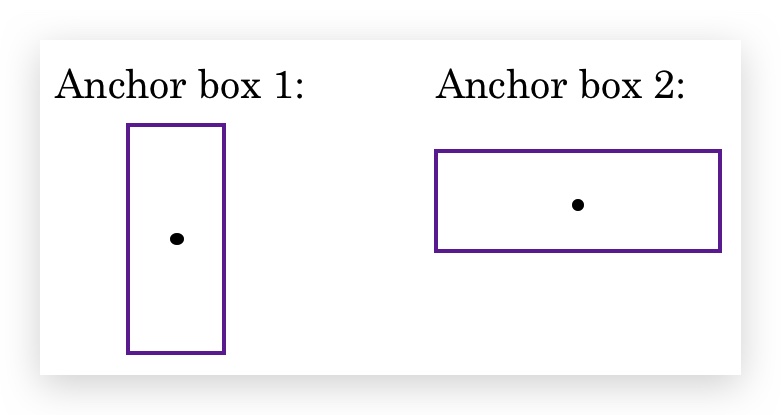
首先将输出的label定义为两个部分(上下两部分的元素和无Anchor box的定义是一样的): \(\\left[ \\begin{matrix} p_c \\\\ b_x \\\\ b_y \\\\ b_h \\\\ b_w \\\\ c_1 \\\\ c_2 \\\\ c_3 \\\\ p_c \\\\ b_x \\\\ b_y \\\\ b_h \\\\ b_w \\\\ c_1 \\\\ c_2 \\\\ c_3 \\\\ \end{matrix} \\right]\)
其中,上半部分对应第一个Anchor Box,下半部分对应第二个Anchor Box。由于人的形状是高瘦的,更接近于第一个Anchor box,因此可以用label上半部分对行人是否存在编码;同样,汽车形状接近于第二个Anchor Box,因此用label下半部分编码。
算法对比:
- 原算法:训练图片中的每个目标,被分配到包含该物体中心点的grid里。
- Ancho Boxes:训练图片中的每个目标,被分配到包含该物体中心点的grid和与其bounding box有最大IoU的anchor box中。相当于增加了一个匹配维度,即(grid cell, anchor box)。
- 本例中,y的维度从3x3x8变成了3x3x2x8。
Anchor Box无法处理的情况:
- 如果设定了两个anchor box,但grid里面有3个物体,则也无法处理
- 如果是两个物体的anchor box一样,也无法处理。
遇到这些情况,只能根据默认的规则随便选一个物体了。
虽然我们用Anchor Box解决两个物体在同一个中心点的问题。但实践中grid切分的比较多,比如19x19个grid,出现两个物体在相同的中心点的概率并不大。除此之外,Anchor Box的作用之一是让你算法更专注训练某种特定物体,比如让某些输出单元专注于高瘦的行人,而另一些输出单元专注于训练宽长的汽车。
如何选择Anchor Box?可以手工选择,也可以用K-means算法聚类,根据聚类的结果选择anchor box。
1.9- YOLO Algorithm
根据前面介绍的内容,我们可以组合成YOLO Algorithm。假设有如下问题用以说明YOLO算法:
我们需要识别图中的三类目标:1-行人 2-汽车 3-摩托车,使用3x3的grid划分,2个anchor box。则label y的维度是3x3x2x8,可表示为:
\[\\left[ \\begin{matrix} p_c \\\\ b_x \\\\ b_y \\\\ b_h \\\\ b_w \\\\ c_1 \\\\ c_2 \\\\ c_3 \\\\ p_c \\\\ b_x \\\\ b_y \\\\ b_h \\\\ b_w \\\\ c_1 \\\\ c_2 \\\\ c_3 \\\\ \end{matrix} \\right]\]首先构建training set,人工查看3x3的grid,对每个grid给出标注值y:
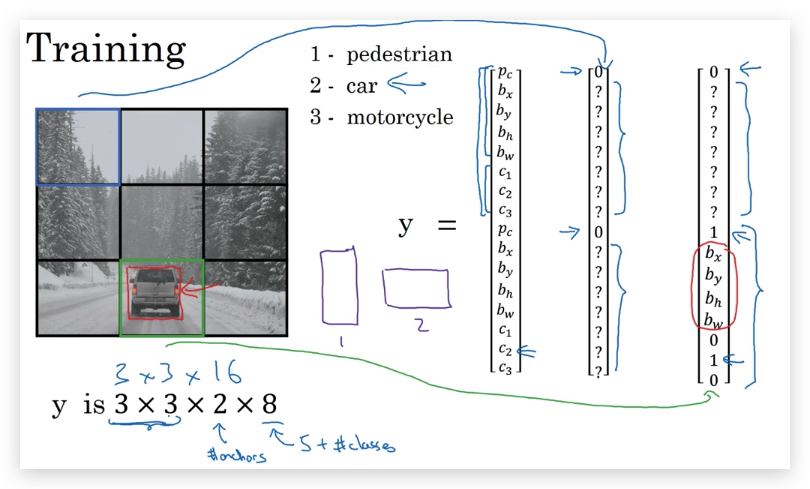
设计的ConvNet,输出volume则是3x3x16,通过这个ConvNet可以输出每个grid的预测值。
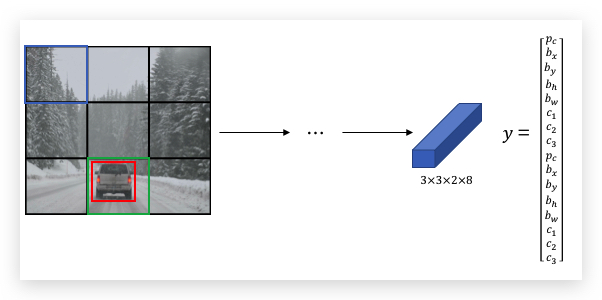
然后通过Non-max Suppression,产生最后的预测值。
1.10- Region Proposals
前面介绍的sliding window或Convolutional Implementation of Sliding Windows,都有一个缺点:在一些空白的,明显没有物体的区域做检测。
R-CNN(Regions with CNNs)的思想是,通过Segmentation algorithm算法(即产生最右面的色块图)找出候选区域,只对有可能出现目标的色块进行检测,输出label和bounding box。相比sliding window的逐行逐列,减少了检测量。

但R-CNN运算很慢,衍生出了改良算法:
- Fast R-CNN:使用Convolutional Implementation of Sliding Windows去识别候选区域。
- Faster R-CNN:使用CNN做候选区域的识别。
即便是Faster R-CNN,也比YOLO慢很多。但Andrew Ng认为,长远看来这是更有前途的算法。
paper参考:
- R-CNN:Girshik et al., 2013. Rich feature hierarchies for accurate object detection and semantic segmentation
- Fast R-CNN:Girshik, 2015. Fast R-CNN
- Faster R-CNN:Ren et al., 2016. Faster R-CNN: Towards real-time object detection with region proposal networks
-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/deeplearning-ai-notes-course4-week3 欢迎指正或在下方评论。