==提示:为方便阅读,《deeplearning.ai深度学习笔记》系列博文已统一整理到 http://dl-notes.imshuai.com==
这是Course 2的内容,涉及:
- 训练集、开发集、测试集的概念
- Bias/Variance问题
- 如何通过泛化(regularization)算法,解决High variance问题,以及常用的集中regularization算法。
- 最小化J中的一些加快手段
- 标准化输入(Normalizing )
- 梯度消失和梯度爆炸问题(Vanishing/Exploding Gradient)以及缓解方法
- 验证梯度计算是否正确。
1- Setting up your Machine Learning Application
1.1- Train / Dev / Test sets
-
Applied ML is a highly iterative process
之所以说是highly interative,是因为要设置不少超参,不断试验。但超参也不是说靠猜。而是通过一些手段,使得这个过程更有效。
- 数据集划分:
- Train set:训练集
- dev set:即cross validation set,测试不同的算法
- test set:测试集
- 关于数据集的一些趋势:
- 传统来说(数据集较小),这三种测试数据的比例为:70%,20%和20%;但在目前大数据集的情况下,dev set和test set的比例并不需要太高,只要足够测试即可,很可能比例是98%,1%和1%,甚至更高。
- 实际生产环境,可能Training set和Dev/test sets来源不同,前者来自开发者,后者来自用户,导致数据集分布不同。
- 经验法则:尽量让Training set和Dev/test sets具有相同的分布。
- 某些情况下没有test set也是没问题的。这个时候只有training set和dev set,或者不严谨的,这个时候dev set被称作为test set(但和tain/dev/test中的test作用并不一样,实际作用还是dev)
1.2- Bias / Variance
Bias:偏差,High bias: underfitting;说明算法比数据简单,不足以描述数据。
Variance:方差,High variance: overfitting;说明算法超过了数据的实际复杂性,甚至将一些随机因素过度解释为了数据规律。
直观的含义:
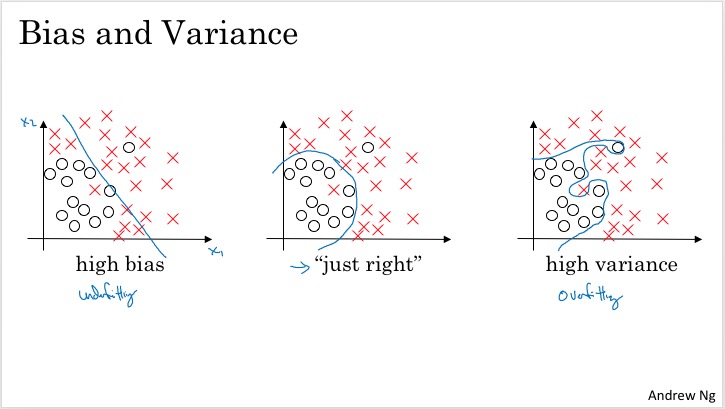
如何衡量是bias还是variance:对比Train set error和dev set error以及base error的关系。
下表是判断依据(括号内的百分数是举例值,假设base error接近0%的error)
| Train set error |
Dev set error |
type |
| low (1%) |
high (11%) |
high variance |
| high (15%) |
high, but near train set error (16%) |
high bias |
| high (15%) |
high, but much higher than Train set error (30%) |
high bias & high variance |
| low (0.5%) |
low (1%) |
low bias & low variance |
可以看出:
- Dev set error理论上通常是大于Train set error
- 好的算法,要求bias和variance都很低,而坏的算法则相反。而并没有一个明显的bias-variance trade-off
人类可以达到的error称作为base error,或optimal error。如果上述表格中,设定的base error=15%,那么第二行的例子反而是low bias & low variance的。
1.3- Basic Recipe for Machine Learning
解决Bias/Variance的一般步骤:
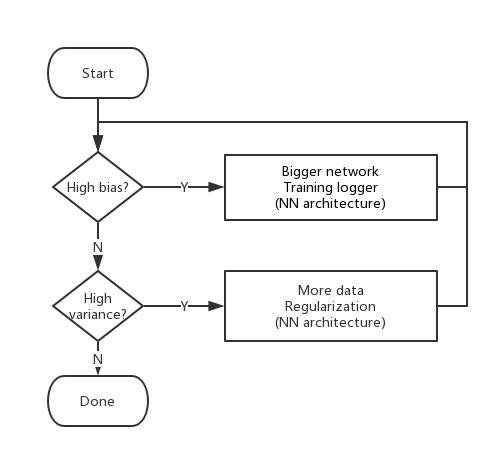
- 针对bias和variance要选择对应的解决方法。
- 在早期的ML,强调bias variance trade-off;但在现代deep learning,可以通过加大Neural Network或增加更多数据,在分别解决High bias和High variance的时候,并不会影响彼此。 这也是deep learning在supervised learning如此成功的重要原因。
Training a bigger network almost never hurts. And the main cost of training a neural network that’s too big is just computational time, so long as you’re regularizing.
2- Regularization your neural network
- Regularzization可以有效解决overfitting问题。
- 常用的regularization方法:
- L2 regularization
- dropout reuglarization
- 我的理解:之所以会有过拟合问题,本质上是数据存在一定的随机性干扰(即在主要的规律外,还有一定的随机因素干扰了数据,而这些随机因素被算法当成规律学习了),而中和这种随机性的办法就是在算法中也增加一些“干扰”,这个“干扰”就是Regularization。
下图是是否做了regularization的对比举例,直观上,regularization 让decision boundary更平滑了:
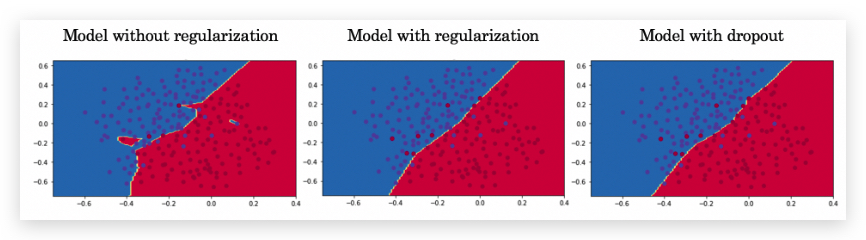
2.1- L2 Regularization
在cost function J 增加参数的\(L^2\)范数,即L2 regularization(也叫weight decay),对于向量来说\(L^2\)范数就是向量的模。
- 举例:
- logistic regression做regularization
在cost function增加:
\(\frac{\lambda}{2m}||w||^2_2\)
- Neural Network,增加Frobenius norm
\(\frac{\lambda}{2m} \sum\limits_{l = 1}^{m}||W^{[l]}||^2_F\)
其中
\(||W^{[l]}||^2_F = \sum\limits_{i = 1}^{n^{[l]}} \sum\limits_{j = 1}^{n^{[l-1]}} (W^{[l]}_{ij})^2\)
其中,λ是regularization parameter
- Why L2 regularization reduces overfitting?
Regularization其实是让函数变得简化。
为什么也叫weight decay?
L2-regularization relies on the assumption that a model with small weights is simpler than a model with large weights. Thus, by penalizing the square values of the weights in the cost function you drive all the weights to smaller values. It becomes too costly for the cost to have large weights! This leads to a smoother model in which the output changes more slowly as the input changes.
加入λ设置的很大,那么整个函数J其实对norm部分更为敏感(因为即norm部分的数值比较大),为了让J更小,就倾向于让W向零靠近;W靠近0的后果是,很多neural起的作用变小了,极限情况下甚至退化为logistic regression。
另外,过大的λ,导致W偏小,同时让activation function(比如tanh)处于偏于线性的部分,有简化的趋势:
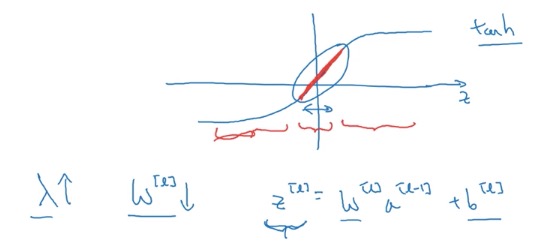
L2 regularization的不足:要通过不断的选用不同的λ进行测试,计算量加大了。
2.2- Dropout Regularization
- Dropout Regularization:在每轮迭代计算时,随机的将Network中一些neuron剔除,效果就好像用了一个更小的Network。(我有个疑问:为什么不直接较小的Network?)
下面是编程作业里面的实例视频
Drop-out on the second hidden layer:
-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/deeplearning-ai-notes-course2-week1 欢迎指正或在下方评论。

毛帅
{Code, Thoughts, Sharing}