deeplearning.ai深度学习笔记(Course3 Week1):ML Strategy (1)
本周介绍了机器学习的策略。强调了方法的正交性,介绍了单值指标并根据情况调整它,以及通过比较人类水平改进bias或variance。
1- Introduction to ML Stratedy
1-1 Why ML Strategy
比如下面识别猫咪的例子,目前训练的结果可以达到90%的准确率。但如果想进一步提高,有很多待选办法,但应该怎么去选呢?接下来的课程就将介绍Machine Learning Strategy。

另外,需要注意,策略并不是一成不变的: It turns out also that machine learning strategy is changing in the era of deep learning because the things you could do are now different with deep learning algorithms than with previous generation of machine learning algorithms.
1-2 Orthogonalization(正交)
构建Machine Learning系统的一个挑战之一就是:有太多的东西可以尝试和修改(比如很多hyperparameter可以调整)。
因此需要了解:调节某项变量,可以得到什么结果,即了解正交(Orthogonalization)。
所谓正交,就是你的操控效果尽量只影响一个方面。比如以老式电视机为例,调节图像的大小、左右偏移、上下偏移。而不是一个按钮可以同时调节图像大小和左右偏移,那样会很难操作。
具体到supervised learning,有以下4个假设是正交的?
- Fit training set well in cost function If it doesn’t fit well, the use of a bigger neural network or switching to a better optimization algorithm might help.
- Fit development set well on cost function If it doesn’t fit well, regularization or using bigger training set might help.
- Fit test set well on cost function If it doesn’t fit well, the use of a bigger development set might help
- Performs well in real world
If it doesn’t perform well, the development test set is not set correctly or the cost function is not evaluating the right thing.
2- Setting up your goal
从某种角度看,机器学习是“测试驱动”的算法,因此设定一个明确的目标或指标很重要。
2-1 Single number evaluation metric
-
用一个单一的指标来评判(一个分数),方便我们在调整算法时有据可依,提高判断效率。而不是又太多的指标,反而无法综合判断了。
-
Precision(精确率)、Recall(召回率)以及F1 Score 对于一个分类问题,根据预测值和实际值会形成下面四种组合情况:

怎么理解四种情况的名称? 第一个是True或False,表示预测是否正确;第二个是预测值,positive表示预测的是1,negative表示预测是0。 比如False postive,positive表示预测的是1,而False表示预测不正确;因此就是实际值是0,而预测值是1。
在上面的区分表上,定义Precision和Recall如下:
- Precesion
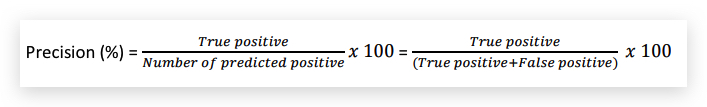 precision用文字表示就是:在所有预测为1的样本中(不管是否真的是1),真的是1的比例。或者说positive检测结果的准确的概率。
precision用文字表示就是:在所有预测为1的样本中(不管是否真的是1),真的是1的比例。或者说positive检测结果的准确的概率。 - Recall
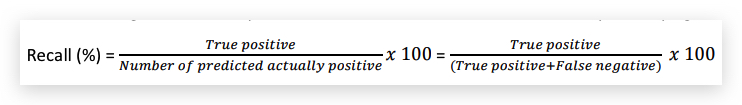 recall用文字表示就是:在所有真的是1的样本中,被算法预测为1的比例。或者说positive样本被算法检测到的概率。
recall用文字表示就是:在所有真的是1的样本中,被算法预测为1的比例。或者说positive样本被算法检测到的概率。
无论precision还是recall,分子都是TP,分母也都包含TP;precision的分母是TP+FP,而Recall的分母是TP+FN。
虽然有precision和recall可以更客观的反应一个分类器的性能,但综合为一个变量更为方便使用;自然想到用平均数,F1 Score就是平均数,确切的说是调和平均数: \(F1 = \frac{2}{\frac{1}{precision} + \frac{1}{recall}} = \frac{2precesion * recall}{precesion+recall}\)
- 补充内容: 为什么不直接用正确率(accuracy)呢?accuracy可以认为是 \(accuracy=\frac{TP+TN}{TP+TN+FP+FN}\)
这对positive比例本身就很小的样本不公平。比如预测癌症样本,1000个样本只有5个是癌症的样本,其他都是正常;那么可以设计一种作弊算法,对所有样本很定的预测为没有癌症,这样仍然能拿到99.5%的正确率,看起来很高,其实没有任何意义。
另外,在实践中一般选择异常的少数现象做positive,比如癌症检测,会将出现癌症的情况定义为1(医院里也是这样的,检测报告若是阳性,说明有问题了),若将正常的大多数情况定义为1,则导致precision和positive看起来都很大。
2-2 Satisfying and Optimizing metric
将所有关心的东西综合为一个单值指标并不容易。
举个例子,如下是针对猫咪识别的二元分类,三种分类器的准确率和运行时间如下:
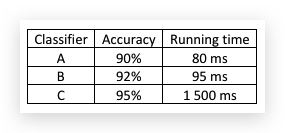
除了准确率外,还要考虑算法耗时,毫无疑问是越准要好,越快越好,但这两个指标怎么结合呢?比如这样: \(cost = accuracy - 0.5 * time\)
这有些主观,更合理的做法是:在可接受的耗时内,尽可能的提高准确性。比如: maximize accuracy s.t. running time <=100ms
如此,accuracy就变成了optimizing metric,而running time则是satisfying metric,statisfying metric只要达到标准即可,而optimizing metric则追求更好。一般的,选择一项metric作为optimizing metric,其他的则设置为satisfying metric:

2-2 Train/dev/test distributions
如何设置Train/dev/test集,很大程度上影响了机器学习的速度。
Train/dev/test的区别 Workflow in machine learning is that you try a lot of ideas, train up different models on the training set, and then use the dev set to evaluate the different ideas and pick one. And, keep innovating to improve dev set performance until, finally, you have one class that you’re happy with that you then evaluate on your test set.
原则: dev/test set保持同一个分布,比如来自同一份数据shuffle后的在拆分的结果。Choose a development set and test set to reflect data you expect to get in the future and consider important to do well.
2-3 Size of the dev and test sets
The guidelines to help set up your dev and test sets are changing in the Deep Learning era.
早期机器学习的建议划分比例:
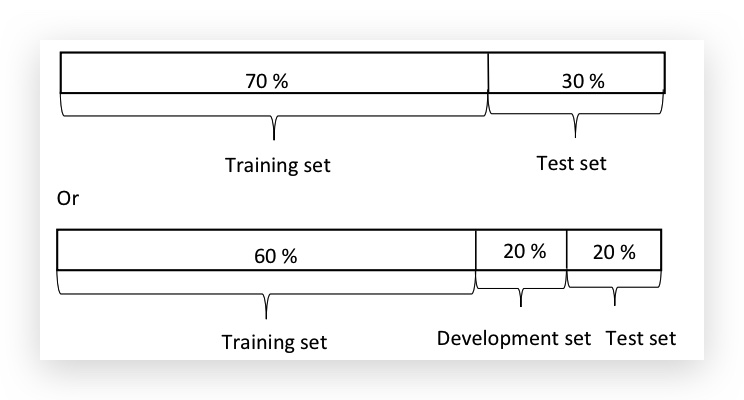
在早期,数据量比较小的情况下,上面是划分比例是合理的。但到深度学习下的Big Data情况下,Dev/Test比例做了很大压缩:
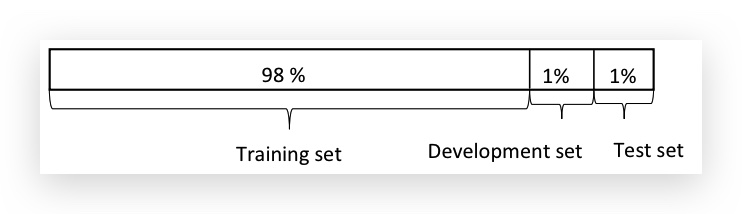
因为在Big Data情况下(比如100万),即便是1%的比例,也有很大的数据集(比如1万条数据)供测试,也是big enough,绰绰有余。
2-4 When to change dev/test sets and metrics
如果发现设定目标和实际期望不符,那就调整目标。
举个例子:设计一个算法,筛选猫咪的图片给爱猫人士。最初设定的metric是classification error,并得到两个算法的结果如下:
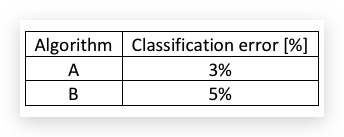
单从错误率指标看,A算法比B算法要好。但因为某种原因,A算法会出现不少色情(pornographic)图片。B算法的错误率高,但却没有色情图片。从这个角度看,B算法更好,但metric却没正确反映。因此要调整metric或者dev/test set。
原始的metric如下:
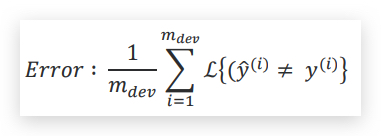 函数统计了错误分类的比例。问题:在于,metric平等的对待了色情和非色情图片,一种解决的办法是引入权重,增加对识别出色情图片的惩罚,首先定义权重w:
函数统计了错误分类的比例。问题:在于,metric平等的对待了色情和非色情图片,一种解决的办法是引入权重,增加对识别出色情图片的惩罚,首先定义权重w:
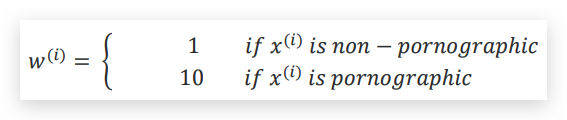 将权重增加到error函数中
将权重增加到error函数中
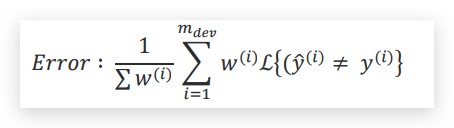 相当于错判一个porn要比错判一个非色情图片的代价差10倍,
相当于错判一个porn要比错判一个非色情图片的代价差10倍,
指导原则:
- 正确的定义评价标准,可以帮助更好的区分算法的优劣。
- 评价标准也需要优化。
题外话:评判结果不好,可能不是你的问题,而是标准的问题!此处不留爷自有留爷处!
另一个例子,一个算法在dev/test set表现的很好,但到实际应用中并不好。比如识别猫咪的算法,在dev/test set使用的图片更清晰,而用户拍摄的猫咪图片可能会模糊,导致实际引用效果没有和dev/test set匹配。这个时候,可能就要根据实际情况,调整dev/test set,使其能正确反映现实数据。
指导原则: 如果metric、dev/test set反映实际应用,则修改metirc或dev/test set (疑问:是否也要修改training set,比如上面的例子,把用户上传的模糊图片加入training set)
最后一个建议:也不要完美主义,在最开始不一定就找到最好的metric和dev/test set,也不要紧,先用起来;在迭代的过程中再不断调整。甚至说不断根据实际情况调整更重要!
# 3- Comparing to human-level performance
3-1 Why human-level performance?
为什么要对比human-level perfomance:
- 第一,由于deep learning的进步,machine learning算法突然产生很好的表现,并在很多应用领域做到人类匹敌逐渐变得可行。
- 构建machine learning的流程中,如果尝试做人类能做的事情,会非常有效。
在接近human-level performance之前,算法提高的很快,但超过之后提高速度逐渐下降。并且存在一个理论上的上界(Bayes optimal error,这是由数据本身的noise决定的):
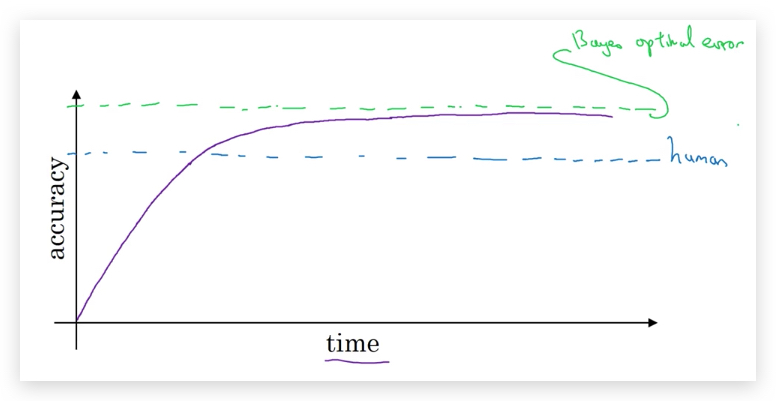
之所以会产生这种前后反差,是因为:
- human-level performance其实已经足够好了,本身就很接近Bayes optimal error。因此留给算法再提升的空间非常有限。
- 在human-level performance之下,人们有特定的工具可以提高performance(相反,超过之后则很难用工具提高了):
- 获取人工标注的数据。
- 人工分析错误的原因,从人类的正确处理得到启发。
- 对bias/variance得到更好的分析。
3-2 Avoidable bias
使用human-level performance作为Bayes optimal error的近似值,据此去考察一个算法的表现,以及是需要降低bias还是variance。
比如,识别猫咪的分类算法,有两个场景A和B得到结果如下:
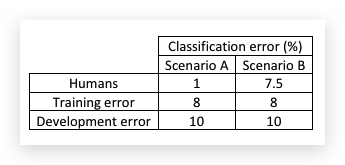 (场景A是比较清晰的图片,人类可以做到1%的错误率;场景B是模糊的图片,即便人也只能做到7.5%的错误率)
(场景A是比较清晰的图片,人类可以做到1%的错误率;场景B是模糊的图片,即便人也只能做到7.5%的错误率)
虽然两种场景下的算法都得到了相同的Train Error和Dev Error,但对待它们的态度是不一样的。
human-level performance一般近似看做Bayes optimal error,我们将Training error和Bayes optimal error(或近似为human-level performance)之间的差距称作avoidable bias。
我们不能盲目的降低training error,因为它是有一个极限的,超过Avoidable bias的部分是不能降低的,除非算法overfitting了。
用avoidable bias的眼光去看场景A和场景B,场景A的avoidable bias(Training Error - Human-level error)有7%,而variance(Dev Error - Tran Error)有2%,因此首要目标是降低avoidable bias,需要采取降bias的收单,比如增大神经网络或增加迭代时间。反观场景B,avoidable bias只有0.5%,而variance还有2%,因此首要任务是降低variance,需要采取降低variance的手段,比如regularization或增加training set。
所以,同样指标,在不同的human-level performance面前,一个是High bias的算法,一个确实High variance的算法。
题外话: 做事情要认识到什么是极限,幻想超越极限是不现实的。同样,明明可以努力做到却没有做到,也是可耻的。
讲到这里,自然会想到底怎么看待human-level performance?又怎么正确的选择human-level performance?即怎么选择做事的极限呢?这就是下一节的内容了。
3-3 Understanding human-level performance
- 用什么作为human-level performance? 在实践中,选择human-level performance并不是唯一标准的,根据不同的场景有不同的考虑。
比如根据X光片做疾病判断为例,不同的人或医生有不用的classification error:
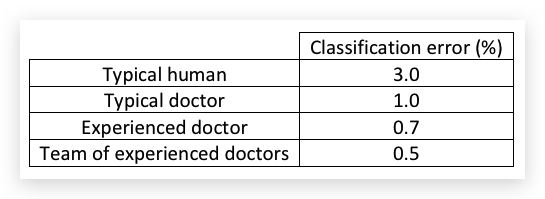
如果human-level performance是被当做对Bayes error的近似,则选择所有人类最好的成绩作为human-level performance,也就是上图的0.5%。
-
如果目的不同,比如是为了部署一个机器学习系统,那么以Typical doctor的1.0%作为human-level performance,那么只要系统能达到或超越这个水平,就可以认为系统表现很不错了。
-
另外,只有当你的算法的Train Error和Dev Error都已经接近典型的human-level,考虑不同的human-level才有价值。比如对于上面X光片的例子,有如下三种场景:
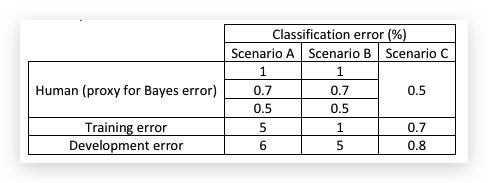
- 场景A:算法只做到了Train Error=5%,Dev Error=6%,那无论选择上哪个doctor的结果,差别都不大(选择不同的human-level,avoidable bias不过是从4%和4.5%的差距),而variance只有1%,更应考虑的是怎样降低Train bias。
- 场景B:算法做到了Train Error=1%,但Dev Error=5%,虽然Train Error已经很接近很逼近Typical doctor了,但Dev error太差了,导致variance高达4%,这个时候考虑哪个doctor做human-level也没有太大意义,更应考虑的是增加降低降低variance。
- 场景C:算法很优秀,这个时候必选选择0.5%作为human-level performance,否则会当做算法overfitting了。此时avoidable bias是0.2%,variance是0.1%,因此要继续降低bias。
题外话:场景A和场景B就好像高考一本线还没过,却纠结是报清华还是上北大,你说是不是想多了?
总结:
- Human-level error是Bayes error的近似。
- 如果human-level error与training error差距比training error和 dev error的差距大,那么焦点应放在减少bias上。(类似场景A)
- 如果human-level error与training error差距比training error和 dev error的差距小,那么焦点应放在减少variance上。(类似场景B)
3-4 Surpassing human-level performance
如果你的算法已经超越了最好的人类团队表现,用人们的直觉去判断算法还有哪些可以改进(bias还是variance)就变得很难了。
比如下面的例子:
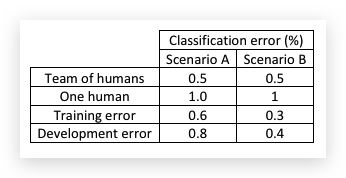
- 对于场景A,很显然要用Team of Humans作为Human-level Error,同时也很容易判断avoidable bias是0.1%,variance是0.2%,因此算法应着眼于降低variance。
- 但对于场景B,无论Train Error还是 Dev Error都已超越人类最好水平。因此Bayes Error应该是小于0.3%的,用0.5%的人类水平已经不能代替Human-level Error了,至于Bayes Error是多少,可能是0.2%,也可能是0.1%,就无可知晓了。没有足够的信息说明要降低bias还是variance。但这并不是说场景B的模型已无法提高了,而是说常规的办法已经没法知道应该降低bias还是variance。
关于机器学习超越人类,已经有很多例子,而且是远超人类,这些例子通常是处理结构化的数据,不属于人类擅长的自然感知问题(natural perception problems,如图像、声音识别),比如:
- Online advertising
- Product recommendations
- Logistics (predicting transit time)
- Loan approvals
即便在诸如图像、声音识别方面,也已有机器学习系统超越了人类。
虽然超越人类水平通常并不容易,但只要有足够的数据,已经有很多深度学习系统已经在单项监督学习问题上超越了人类。
3-5 Improving your model performance
补充两点:
- 首先要很好的匹配Training Set,即尽可能的降低Avoidable Bias。
- 在Training set上的良好表现很好的泛化(generalize)到dev/test set,即variance要低。
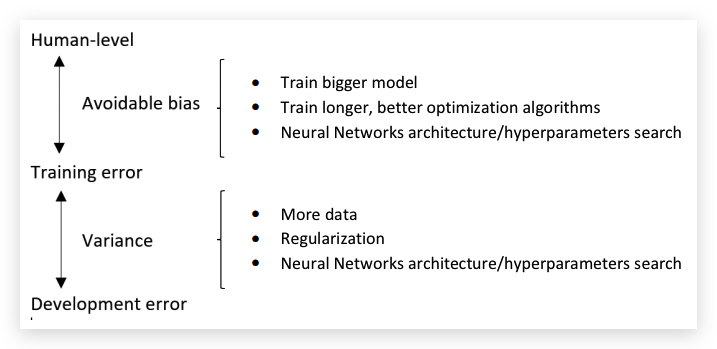
总结起来,可以分别采取的(正交的)办法有:
Andrew Ng对本周的课程的评价:Easily learned but hard to master.
-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/deeplearning-ai-notes-course3-week1 欢迎指正或在下方评论。