deeplearning.ai深度学习笔记(Course3 Week2):ML Strategy (2)
本周继续介绍了机器学习的策略。包括如何做错误分析,如何处理training与dev/test分布不一致的情况,以及最新发展的迁移学习、多任务学习以及end-to-end学习。
1- Error Analysis
1.1- Carrying out error analysis
如果你的机器学习算法表现还不好,那么手工去分析算法犯的错误,可以给下一步改进算法提供线索,这个过程即error analysis
一个案例: 团队开发的识别猫咪的算法,目前在dev set上已达到90%的正确率。分析算法误识别的样本,发现有狗的图片被误识别为猫,那么是否需要针对狗的图片专门进行优化?比如搜集更多的狗图片,或者增加针对狗的feature。
是否立即针对狗图片优化?更明智的做法是先做error analysis,再决定:
- 搜集100个算法误识别的example(mislabeled examples)
- 计算一下其中有多少是狗的图片
如果100个中只有5个是狗的图片,说明这种情况并不普遍,即便下功夫完全解决狗被识别为猫的问题,最多也是把正确率从90%提升到90.5%的上限(ceiling)而已。因此这不是目前的要务。 反之,如果100个中有50个是狗的图片,则很有必要针对狗图片进行优化。理论上,可以让正确率提升到95%,这是值得的。
也许在机器学习领域,我们会鄙视手工工程或加入太多人为观点;但从构建应用系统的角度,做一点微小的工作(error analysis),可以为决定如何优化算法明确方向,节省大量时间。
类似的,在分析mislabeled example时,可以把错误的原因做一个分类,统计每种错误的占比,决定哪些问题要优先解决。比如上面的例子,可以分析:狗图片误识别、大型猫科动物无识别、图片太模糊等等,比如做一个下面的表格进行分析:
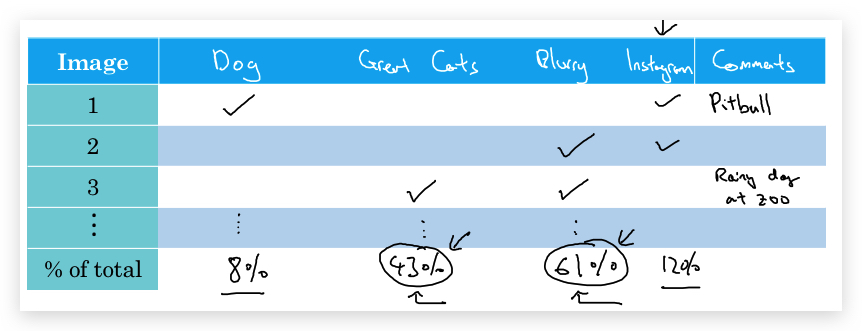
1.2- Cleaning up incorrectly labeled data
两个术语:
- mislabled examples:算法预测的错误的样本。
- incorrectly labeled examples:数据集(包括training/dev/test)中被错误标记的样本,一般是人为失误。
如果发现数据有incorrectly labeled exmpales,如何处理?
- 如果出现在training set 深度学习算法对training set中的随机误差(random errors)是相当健壮的(robust),只要training set中的incorrectly labeled exmpales足够随机(比如录入时敲键盘敲错了)且数量较小,完全可以不用关注,不用修正。但不能出现systematic errors(比如总是将白色的狗标记为猫),这会影响算法。
- 如果出现在test/dev set 在error analysis的时,增加一列“Incorrected labeled”,分析其比例:
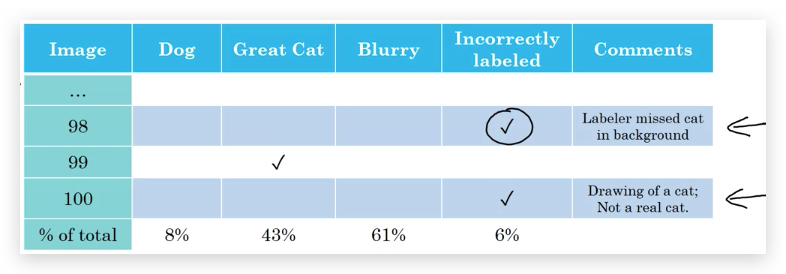
同其他error analysis一样,也是看影响是否严重。如果影响不大,则可以不考虑这个问题(至少暂时不是首要任务)
在修正dev/test set的incorrectly labeled examples时的指导原则:
- 对dev和test set要使用相同的处理方法,保证它们始终保持相同的分布。
- 检查算法正确预测的样本,是否存在incorrectly labeled和msilabeled同时出现的情况(比如一个图片不是猫,但dev/test集被人员mislabel为了猫,同时算法也预测这个样本为猫)。这一部分的偏差,会导致算法的正确率被不正确的高估了。 但此项工作的成本较高,毕竟正确预测的样本远大于错误预测的样本;一般可以不做。
- 针对dev/test set的修正,会导致其与training set分布略有不同,但问题不大。
一个疑问:会不会存在incorrect examples同时也被mislabeled?错上错变成正确。
Andrew Ng的建议:
- Deep learning 研究人员,会认为只是给算法喂入大量数据,训练算法就行了;但至少对构建应用系统的应用领域,不仅要喂数据,还要手工的做error analysis并加入人类洞察(human insight)。
- 有些工程师和研究人员非常反感手工查看数据,但实际上这种手工工作并不会花多久时间,但效果很好。即便Andrew Ng,现在也会经常手工的去做error analysis。
1.3- Build your first system quickly, then iterate
重要建议: Build your first system quickly and then iterate.
构建一个具体的机器学习应用,涉及到方方面面的优化,比如Speech Recognition,可能需要考虑:背景噪音、方言、离麦克风太远、儿童语音、口头禅等等。与其去考虑这么多复杂情况,更重要的是快速开始,而不是一开始就搞这么复杂。
- 设定 dev/test set和metric:设定目标
- 快速构建初始版本
- 快速训练训练集:匹配出parameter
- dev set:调优参数
- Test set:评价性能
- 使用Bias/Varaince 分析、Error analysis决定下一步优先做什么。
题外话:一开始不要太完美主义。最重要的是开始,而且是现在就开始。
2- Mismatched training and dev/test set
2.1- Training and testing on different distributions
虽然我们一直强调:train/dev/test set保持相同的分布,但现实情况可能做不到:
- 用户产生的数据和训练时产生的数据有所差别
- 用户产生的数据还很少,因此采用了其他来源的数据(比如购买的数据)
比如识别猫咪的例子,训练时用的是从网上搜集的高清猫咪图片(20万张),而用户通过APP上传的是较模糊、构图奇怪的猫咪图片(1万张)。

我们的算法会表现较差,但识别用户上传的猫咪图片才是真正重要的。于是希望把1万张用户上传的图片加入到算法的训练中。问题是这1万张图片如何分配到train/dev/test中呢?
-
方案1: 将20万高清和1万张用户图片混杂在一起(shuffle),然后按比例切分出train/dev/set: train set变成了20.5万,dev/test set都是2500张。 这个做法的好处是train/dev/test set保持相同的分布。坏处是dev/test set中分别只有100多张用户上传的猫咪图片,比例太小,仍然无法反应现实世界。这样训练,仍然是设置了一个错误的目标。可以预见,结果不会有太大提升。
-
方案2: 将1万张用户图片拆分5000张给Training set,dev/test全部都是用户上传的图片,各占2500张。 这种做法的好处是:dev/test set完全反映了真实目标。问题是:train/dev/test set分布变得不一样(mismatched data distributions)。
方案2要比方案1效果更好。在这种情况下,让目标准确比保持相同分布更重要。
2.2- Bias and Variance with mismatched data distributions
Training error与dev/test error可以帮助分析bias和variance,当training set与dev/test set的分布不一致时,bias和variance分析的方法也要改变。
举例: 以前面讨论的识别猫咪的例子,如果Human-level error大约为0%,Training error是1%,Dev error是10%。并不能简单的认为,这是variance问题。导致Dev error过高的原因可能是数据分布差异,即data mismatch问题。
那如何分辨Dev error过高的真实原因呢? 只要引入training-dev set,即和training set具有相同分布,但不用于training的数据。
引入training-dev set后的数据划分结构如下:
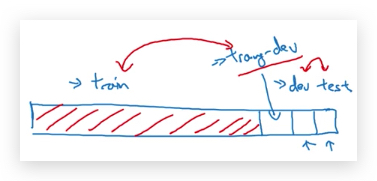
在training-dev set上的error就叫做training-dev set error。training-dev error与dev set error的差距,反映了Data mismatch,最后形成如下的关系:

据此,即可分析出Dev test error过高,到底是Variance还是Data mismatch问题。举例如下:
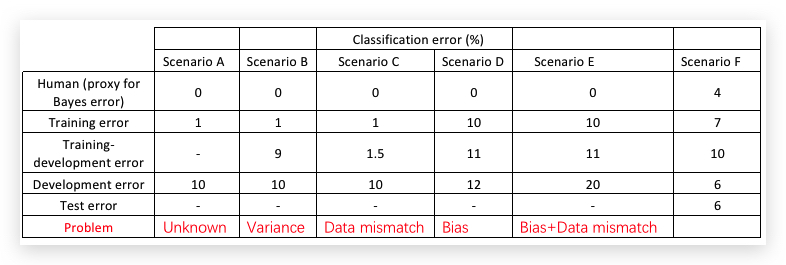
2.3- Addressing data mismatch
首先,data mismatch是由于数据分布不一致引起的,没有完全的系统性的解决办法。
指导原则是:
- 做手工的Error Analysis,理解Training set和Dev/Test set的差异。
- 制作或收集与Dev/Test set相似的数据。为此,可以是人工数据合成数据(Artificial Data Synthesis),比如Training set都是在安静环境录制的,Dev/Test set含有环境噪音,可以对Training Set做环境噪音叠加。总之,原则是尝试让数据在关键的维度上与Dev/Test set更相似。
关于人工数据合成,由于合成的数据只是现实数据的一个很小的子集(比如用一个小时的环境噪音去叠加1万小时的原始声音数据),Neural Network可能会对人工合成数据overfitting。
3- Learning for multiple tasks
3.1- Transfer learning
迁移学习(Transfer Learning)是指将在一个已学习的神经网络结构应用到另外一个任务上。这也是Deep Learning最强大的思想之一。
举个例子,猫咪识别迁移学习到X光片疾病检测:
针对猫咪识别,输入图片,输出1-有猫,0-没猫
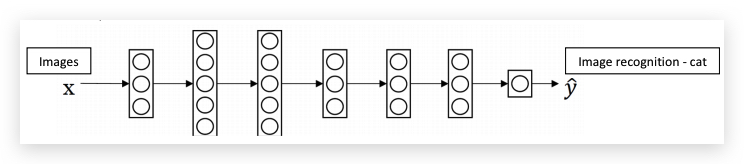
X光片疾病检测,输入X光片图片,输出1-恶性肿瘤,0-良性肿瘤
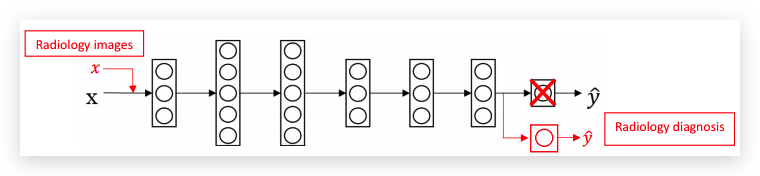
把已经学习好的猫咪识别Neural Network迁移到X光片疾病检测:
- 将最后的输出改为肿瘤恶性与否
- 并随机初始化后最后一层的参数W和b
- 将X光片图片数据输入到Neural Network中,重新训练。
关于第3步的训练,如果数据量较小,可以固定前面已学习的参数,只训练最后一层或两层的参数;如果数据量充足,可以重新训练整个网络的参数。
如果是重新训练整个网络参数,那么在迁移前训练也称之为预训练(Pre-training),因为迁移学习之前训练的参数,被用作迁移学习时对网络参数的预初始化(pre-initialize),而不是随机初始化。接下来,在新任务上的学习则称之为微调(fine-tuning)。
对迁移学习的理解:在很多底层(low-level)feature的学习上(比如检测边界、检测曲线),两种任务中是相通的。可以让新的模型学习的更快,或者用更少的数据学习。
另一个例子:在一般的speech recognition系统上构建wakeword/triggerword detection(即设备唤醒关键词,比如Ok google)。 迁移学习的网络,也可以在原有的网络输出层砍掉后,再对接上一些隐藏层。
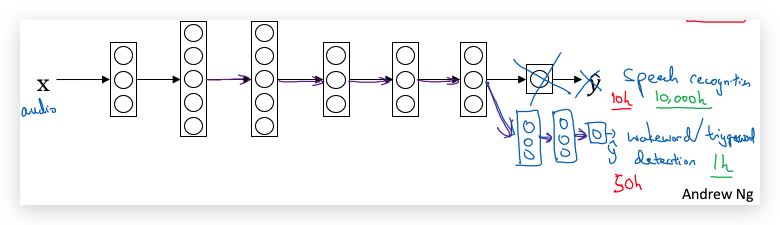
合理的迁移场景:从一个已经训练了大量数据的应用迁移到一个数据量相对较小的应用,比如:
- 从一般的图像识别迁移到X光片疾病检测。前者可能已经训练了数百万数据,而后者只有几百个数据。
- 从一般的speech recognition,迁移到只有wakeword detection。前者已经从数万小时的声音数据训练了对人类声音特征的理解。在此基础上只要训练几个小时的warkword声音数据即可。
总结,什么时候考虑用迁移学习?如果要从任务A迁移学习到任务B,要求:
- A和B有相同的输入,比如都是图片或都是音频。
- 任务A拥有远多于任务B的数据。
- 任务A中的底层feature要对任务B有用。
3-2 Multi-task learning
Transfer Learing是一个串行过程,学完A再迁移到学B上面,而Multi-task learning则是并行学习,使用一个Neural Network同时做多件相似的任务。
举例: 在自动驾驶中,需要同时识别多个物体:行人、汽车、路标、红绿灯、自行车等。当然,可以用多个neural network分别训练识别每个物体。但在这种情况下,一个neural network同时训练多个任务要比分别训练性能要好。因为,这些并行训练的任务在前层网络具有共性的隐藏feature,从原理上看和Transfer Learning是相似的。
与单个任务训练不同,neural network的输出是多维标签,比如:
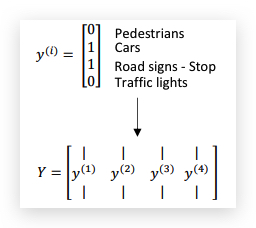
Neural network的架构和单个样本的loss function如下:
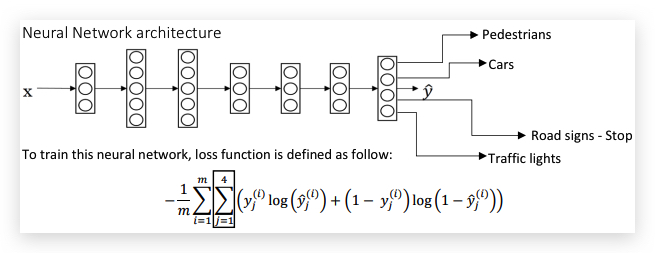
当然标记数据并不一定每一条都对每个任务标记,没有标记的可以用留空(下图的?),在计算loss functio的时候,跳过这些没有标记的数据:

Multi-task learning和softmax的区别
下图是softmax的示意图(具体参考deeplearning.ai深度学习笔记(Course2 Week3):Hyperparameter tuning, Batch Normalization and Programming Frameworks):
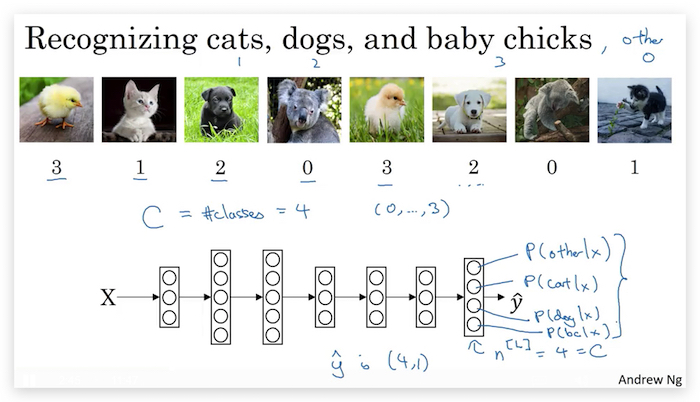
- 虽然最后的输出层看起来是一样的,但softmax最后的\(\hat{y}\)是一维的,但multi-task的\(\hat{y}\)仍然是多维的。
- 样本上数据上,softmax也是一条数据一个label,而Multi-task一条数据有多个label。
multi-task learning合理的应用场景:
- 并行的任务拥有共同的底层(low-level)feature,比如同时识别图片中的行人、汽车、红绿灯。
- 并行训练的每一项的任务的数据量要基本一样。每一项任务都会受益于其他所有任务的学习结果。
- 最好训练足够大的Neural Network,这样才能在multi-task learning上取的较好效果。
总结:
- 实践中,multi-task learning要比transfer learning应用的少很多。
- computer vision中应用multi-task的场景比较多,同时需要在一个画面中识别很多物体。
4- End-to-end deep learning
4.1- What is end-to-end deep learning?
Deep learing近期最令人兴奋的发展之一就是end-to-end deep learning。
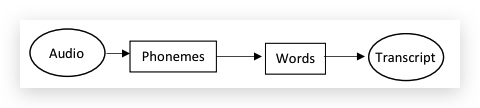
传统的deep learning,一般会将学习任务拆分为多个步骤(pipeline)分别实现(还记得在Machine Learning课程中的Machine Learning Pipline吗?),比如Speech Recognition,从Audio到文本要经过几个中间步骤:

这个过程,也包含了一些手工工作,比如使用MFCC算法从audio中提取特定的hand designed futures。
而end-to-end deep learning非常直接,省去了中间的所有步骤,直接用一个neural network训练输入到输出,比如上面的例子可以变成:

End-to-end deep learning对传统的deep learning有一定的挑战,传统的deep learning中的中间步骤非常重要,对此有很多研究人员做了很多研究工作,比如特征工程(engineering feature).
但End-to-end deep learning的一个重要挑战是,必须有大量的数据,才能表现出好的性能。当数据量小的时候,传统的pipeline会表现的更好。但当数据量足够大,而且neural network足够复杂,End-to-end deep learning要好于传统的pipeline。
如果数据量中等,折中的End-to-end deep learning,可以只跳过pipeline中的一部分,比如例子中跳过extract features:
传统的pipeline在数据量少的领域,可以显著改善学习性能。比如闸机上使用人脸身份识别。在样本少的情况下,通常会拆分成两个步骤:
- 先从图片中定位出人脸部分
- 针对人脸部分训练是否和目标照片匹配。
pipeline在数据量少的领域,可以显著改善学习性能,主要原因是:
- 加入了人的认知。比如上面的例子,身份识别的要点是人脸,因此需要先定位人脸。(虽然这可以加快学习,但反过来人类的认知也是一种偏见,会丧失一些隐含信息,而本来是模型可以学习到的,比如本例中,人的身高、姿态、着装也和身份识别有一定的关系,这就是被武断的去除了。相信在end-to-end deep learning中,算法会捕捉到这些细节。)
- 拆分后的每个步骤可以单独训练,单独训练的步骤能搜集到更多的数据。比如上面的例子,可以分别训练照片扣脸和人脸比对两个任务,而这两个任务可以分别搜集的素材就多得多。如果用的end-to-end leanring,那么能搜集的素材仅限于闸机上拍的照片。
总结: end-to-end learning的优点:可以简化构建过程,省去了构建很多手工设计的组件的过程,而且可以捕捉到比人类认知更丰富的信息。缺点是需要大量的数据,因此并不是对所有场景都适合。 目前比较适合场景有:音频转文字、图像捕捉、图像合成、机器翻译、自动驾驶。
4.2- Whether to use end-to-end deep learning
要不要应用end-to-end deep learning的关键原则是:是否有足够的数据学习一个复杂的函数映射X到Y。
应用end-to-end deep learning优缺点:
优点:
- 让数据说话。纯粹的机器学习过程,让neural network找到数据里隐含的统计信息,而不是被强迫使用人为的先入为主的偏见。
- 更少的手工设计组件(less hand-designing of components),简化设计流程。
缺点:
- 需要大量的标记数据。
- 摒弃了可能很有用的手工设计组件。learning algorithm的知识两大来源:1. Data 2. hand-design。如果数据量较小,hand-desgin是注入人类知识到算法的途径之一。
-------------------------
本文采用 知识共享署名 4.0 国际许可协议(CC-BY 4.0)进行许可。转载请注明来源:https://imshuai.com/deeplearning-ai-notes-course3-week2 欢迎指正或在下方评论。